请教大家,我通过paraview打开一个实例之前保存的state file,但是一加载就闪退。请问这个是什么原因?
S
sjlouie91
@sjlouie91
帖子
-
-
@李东岳
您好李老师,针对这个波动,我之前也发现了,但是我后续又计算过一次,最终320核计算用时577s。总之,就是在240核以上基本上就不太有效果了。
针对您提到的这两个算例,我测试一下。 -
@number44
感谢你的建议。如果不是CPU的问题的话,有没有可能瓶颈在硬盘读取上?
我还有个疑问,我之前在LES算例上测试过GAMG求解器,一般来说GAMG计算更快,但是我不清楚是我设置有问题还是其他别的什么原因,我在使用GAMG的时候计算异常缓慢。
这个是我之前的计算设置,请问是否有针对这个算法的较优的设置参数?

-
@李东岳
应该走的是infiniband,我还试过更改-genv I_MPI_FABRICS shm:ofi为shm:dapl,但是提示只有shm:ofi和ofi两种。
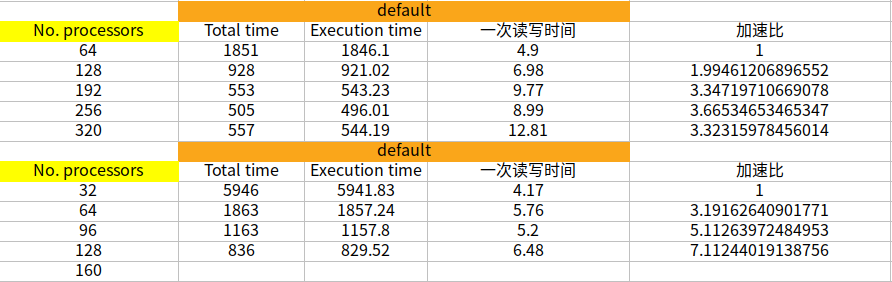
此外,除了一个节点使用32核心,我还测试过1个节点使用48和56核心,我发现不知道有没有可能是计算瓶颈的问题,我只要是用到240核上,每步计算的时长就没法再减小了。1节点64核100步,总共1851s 2节点128核100步,总共928s 3节点196核100步,总共553s 4节点256核100步,总共505s 5节点320核100步,总共557s 1节点32核100步,总共5946s 2节点64核100步,总共1863s 3节点96核100步,总共1163s 4节点128核100步,总共836s 5节点160核100步,总共616s 5节点240核100步,总共526s 5节点280核100步,总共567s请问李老师你们测试采用的算例是什么?
-
@李东岳 李老师您好,除了刚才发的OpenFOAM的测试性能以外,关于Fluent测试的效果是5个节点的加速比符合线性scale。
-
@xpqiu 您好,感谢您的回复。
关于-genv FI_PROVIDER tcp,我测试过,必须得加上这个参数,否则没办法计算。至于shm:ofi,我发现好像是否添加这个参数对结果影响不大。 -
@lzf 还有一个问题想请教一下,你们使用集群计算模块加载的除了intel和intel-mpi,是否还需要其他什么模块吗?
如果可能的话,能否私信告诉我一下你的联系方式方便沟通并行相关问题? -
@lzf 你好,抱歉回复的晚。请问你指的结果是说最后计算时长吗?还是指的流场结果?
这个是我测试的加速比曲线和计算时长。如果有需要,我可以提供算例cavity文件
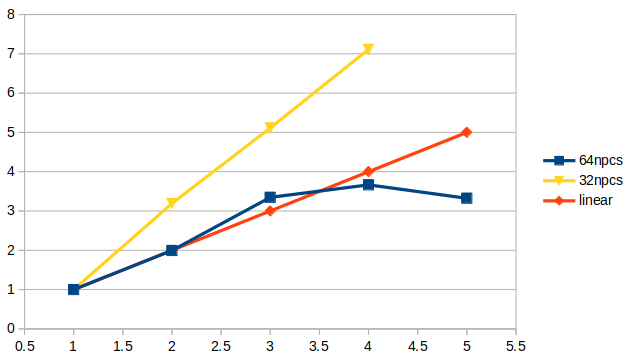
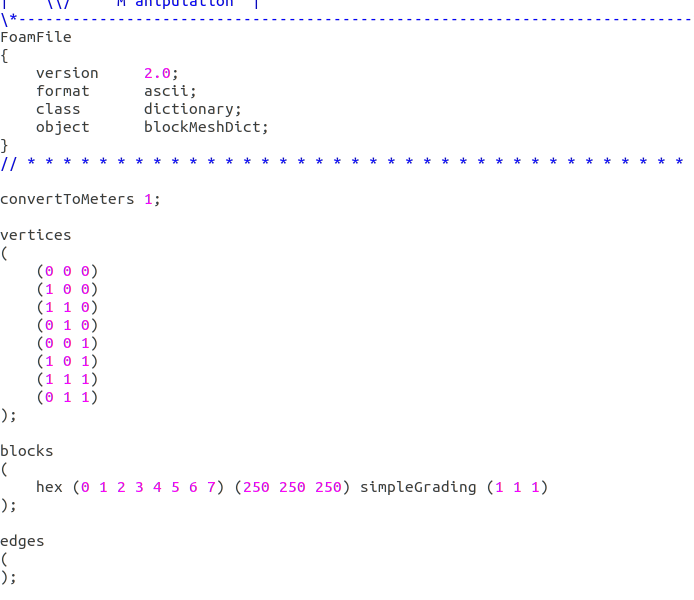
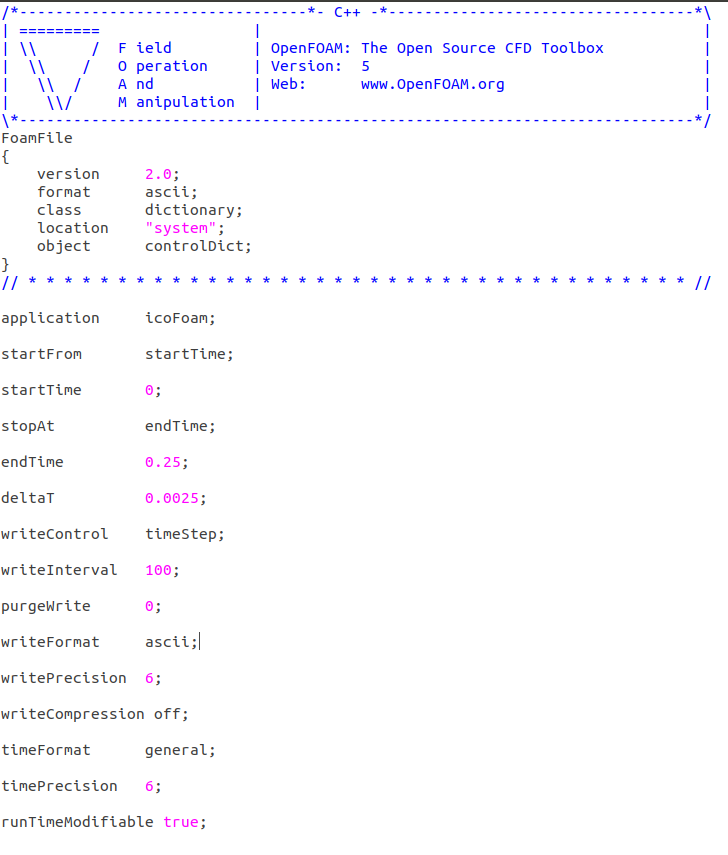
cavity算例的计算设置文件blockMeshDict,controlDict,fvSolution如下,fvSchemes采用tutorials中的设置:
blockMeshDict
controlDict
fvSolution

-
@李东岳 李老师,您好。我按照您的建议进行了测试,但是每个节点跑满所有核时,在3个节点时还可以实现线性,但是5个节点反而变慢。
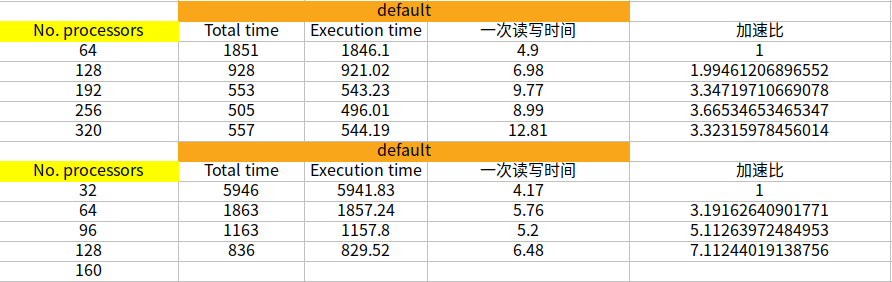
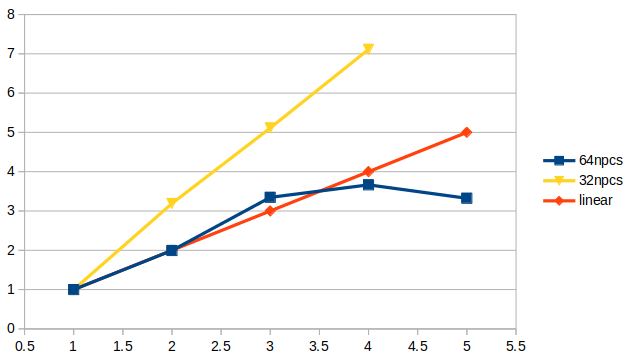
请问这种情况还有可能是并行哪里有问题呢? -
@李东岳
请问这种有问题吗?
-genv FI_PROVIDER mlx -
@lzf
好的,感谢! -
@lzf
好的,我试试。请问这个命令是会影响到并行效率吗?抱歉,我不太懂MPI相关命令 -
@李东岳
好的,谢谢李老师,我先测试一下。 -
@lzf
你好,请问指的是什么命令?是提交任务的命令吗?
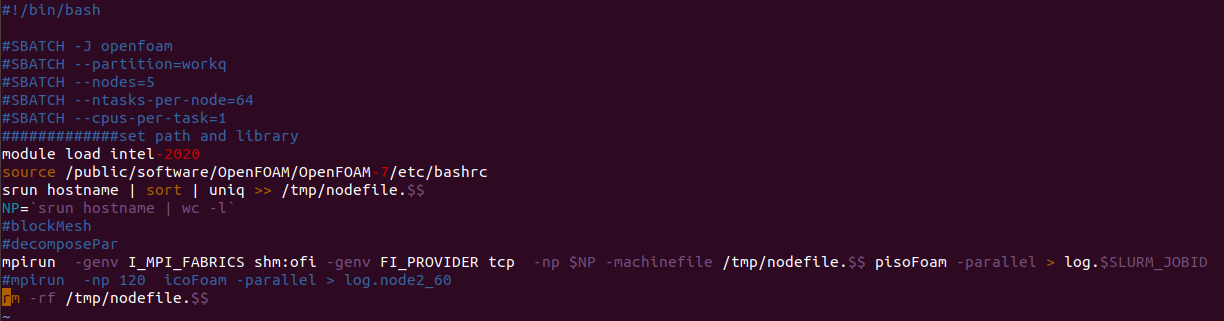
-
@李东岳
李老师,我是按照单节点64核,双节点128核,以此类推来测试的。目前主要测试的是空腔算例和我自己的LES算例。- 空腔算例:1500万,icoFoam,我是一共运行了100步,平均计算每步运行时间。
一个节点64核心:平均单步19.18s
五个节点320核心:平均单步7.1s
可以看到并行加速比明显未达到预期。我在超算平台上测试过128核心,采用完全相同的计算设置,平均单步6.65s - LES算例,2000万,pisoFoam,同样运行了100个时间步。
这个算例我仅仅测试了256核心和320核心,因为我之前计算的时候采用的就是300核心左右。
我同时测试了每步跑满1000迭代步和最大迭代步设置为100迭代步的情况,以下是具体的数据:
五个节点320核心,最慢平均每步26s,最快平均每步9.2s
四个节点256核心,最慢平均每步29s,最快平均10.5s
作为参考,在超算平台上,同样的算例,336核心,平均每步5s左右。
所以很明显并行测试不达标,主要是因为我们在fluent里测试没有问题,主要问题就在于openFoam,所以目前不知道该怎么解决这个问题。
- 空腔算例:1500万,icoFoam,我是一共运行了100步,平均计算每步运行时间。
-
@bestucan 在 集群上并行测试OpenFOAM,并行效率并没有比单节点提升 中说:
比表现性能也没有比只核数的呀

比核数,安桌手机超过苹果。
要看处理器型号、主频,硬盘读写速度,有木有阵列,还有BIOS设置什么的。
测算力用 linkpack benckmark 什么的。自己搞得,简单的测不出来,复杂的容易设置错。
感谢您的回复,我们具体的配置是:
infiniband交换机带宽:56Gbps
CPU型号:英特尔至强铂金8375C (每节点双路共64核)主频3.5GHz
硬盘:东芝企业级14T*6,组raid6阵列,系统安装在固态硬盘内
BIOS设置过,但是跑FLUENT速度正常,所以猜测BIOS应该没有大问题有关于测试算例,我采用的1500万网格就是最简单的空腔算例,因为之前我们用过国内的超算平台,我也测试过这个算例。请问,你说的benchmark应该是哪些?是李老师在网站上提到的qDNS吗?还是别的什么?我不是很清楚,请教您一下。
谢谢!
-
@李东岳
李老师您好,我们的并行计算相关设置都是购买集群的时候帮我们配置的。具体的配置如下:
infiniband交换机带宽:56Gbps
CPU型号:英特尔至强铂金8375C (每节点双路共64核)主频3.5GHz
硬盘:东芝企业级14T*6,组raid6阵列,系统安装在固态硬盘内
总共花了31万多一点Openfoam-7
bashrcfile:
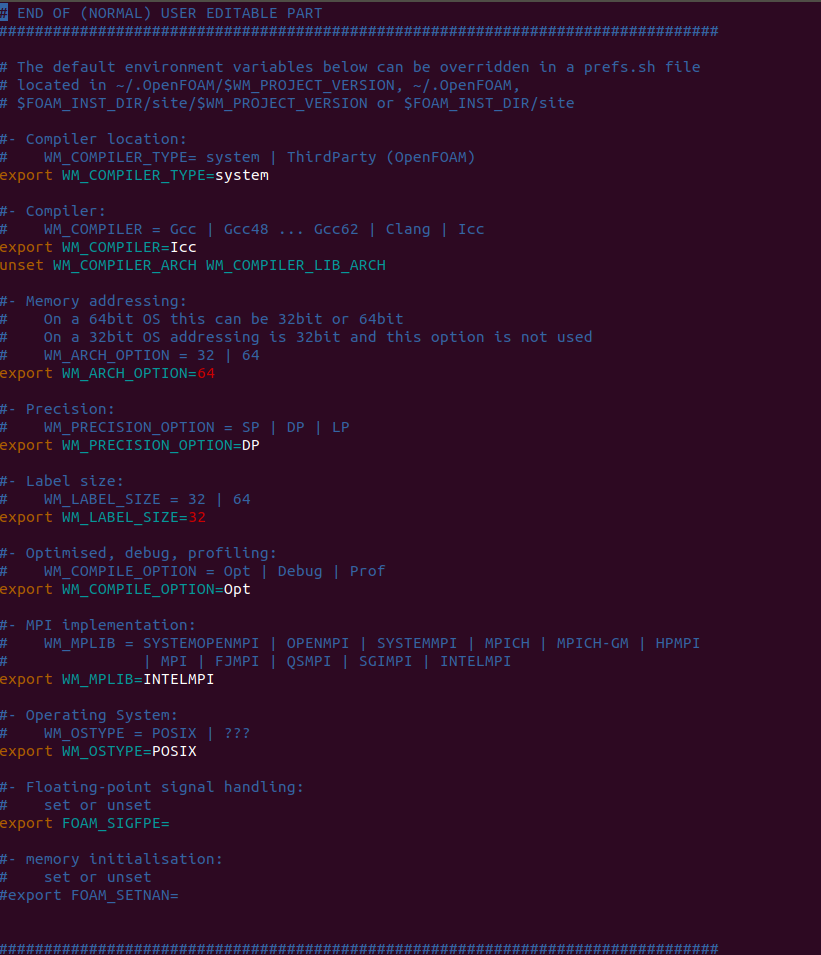
-
请教大家,我在课题组刚配置的集群上测试OpenFOAM并行效率,一共有320核心,单节点64核心。
我测试1500万网格的算例,单节点运行单步大约19秒,当采用两个节点时,单步11.5秒,并未提升明显。进一步增至3个节点时,计算反而减慢。
第二个LES算例,2000万左右网格,在其他超算平台上测试过采用336核心大约只需要5-6秒,但是在我们自己的集群上我采用4-5个节点,最快都得20秒,明显跨节点通讯有问题。
我采用的编译器是Intel-2018和IntelMPI。因为我们还测试过FLUENT的并行效率,没有出现问题,所以猜测不是硬件的问题,请问有可能是openfoam哪里配置出现问题?
-
@李东岳 李老师,您好,我按照您的建议进行了相关的测试。结果发现当更换为GAMG时计算比PCG慢非常多,如果我在计算一开始取残差与相对残差值较大时,完全不收敛的情况基本上到500步左右就改善了。但是我又发现一个特别奇怪的现象:
首先通过pimpleFoam (nOuterCorrectors=1) 计算到一定步时计算结果收敛很好,残差基本下降至1e-5左右;但是当我在运行时更改nOuterCorrectors=2时,初始残差立即上升至0.4左右,计算异常缓慢,并且继续运行算例残差也下降不了。请问这个可能是什么原因导致的呢? -
@李东岳 是压力p的残差每步多要计算1000步。下面是我的计算设置文件,李老师您看是否有什么问题?
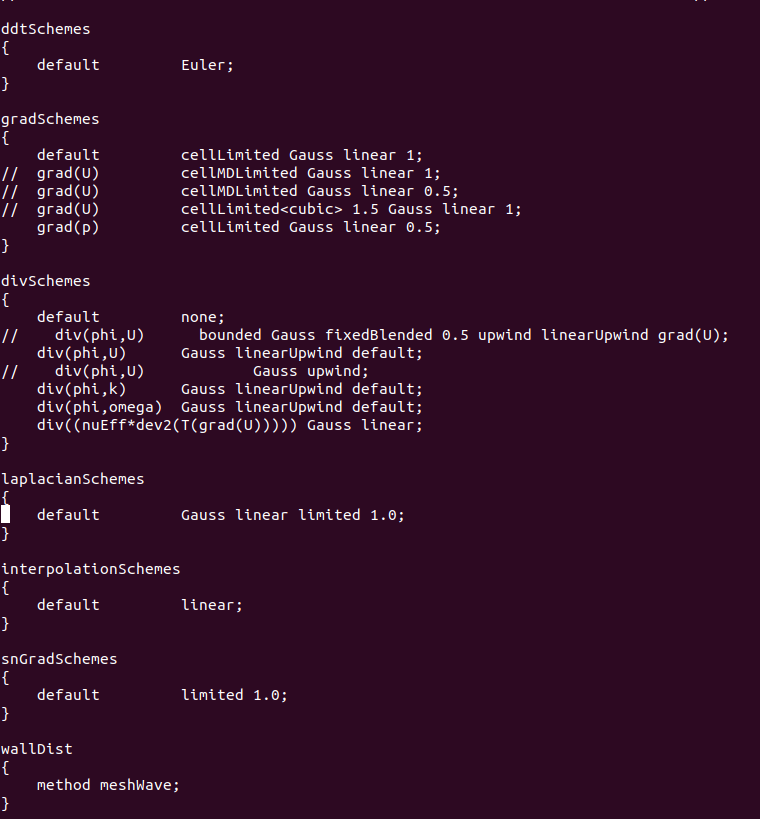
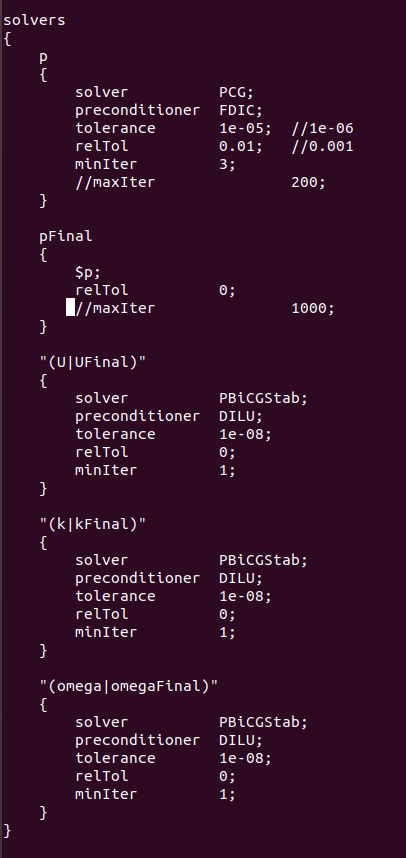
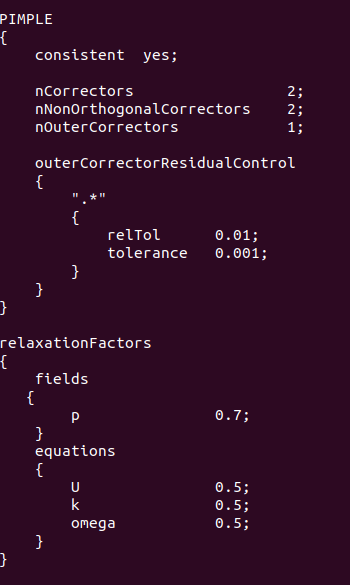
-
@李东岳 好的,主要是时间步长太小了。还有,请问李老师,我计算时每一步计算都很难收敛,都要计算到1000步才结束,我修改了相对与绝对残差,想着初始计算加快些,但是结果也很难收敛,请问有什么办法改进吗?
-
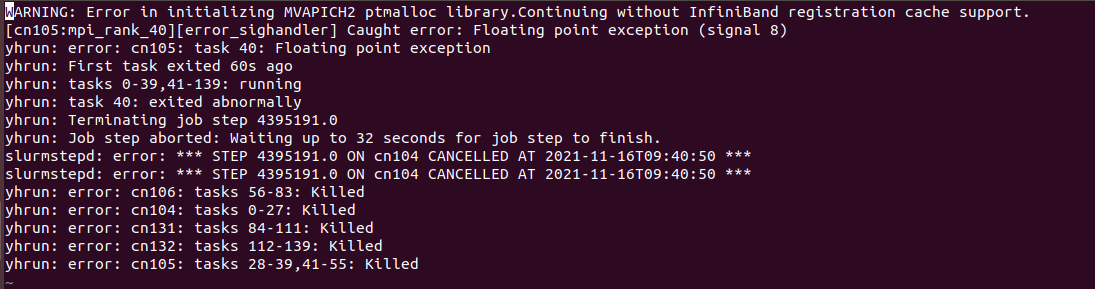
请问大家,我在用pimpleFoam求解器,当nOuterCorrectors=1,2时均可以运行,一到第三次迭代就报错"floating point exception"。请教是什么原因造成的?
下面是我的fvSolution的设置部分与报错内容
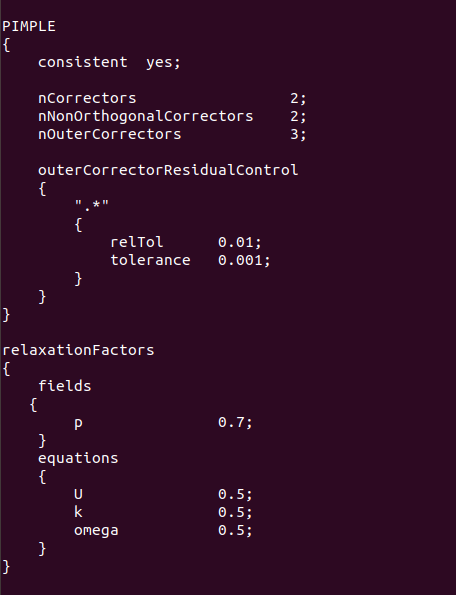
-
并且我发现就算我没有最终安装of8,只执行之前的
sudo apt update一系列命令,也会出现该问题。。。 -
请问大家,我之前安装过of5x和of7,当时安装完并行计算都没有任何问题,但是我按照网站上安装教程重新安装了of8以后,在of8并行计算没问题,但是之前版本的of5x和of7均出现以下问题。请教各位这是什么原因?
-
@李东岳 李老师,您好。我看今年的两次都是OKS课程,请问什么时候会开设OKS2课程呢?
-
请问大家,
我在Ubuntu 18.04上编译安装OpenFOAM-5.x。到了修改配置文件这步
gedit $HOME/.bashrc我添加了
source $HOME/OpenFOAM/OpenFOAM-5.x/etc/bashrc之后打开新的终端显示下图:
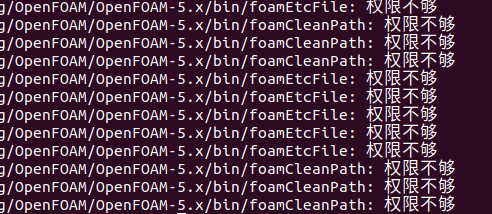
然后我又在bashrc里添加了sudo命令,可是又出现source 找不到命令;并且输入./Allwmake也是找不到命令有人知道这种情况该如何解决吗?
-
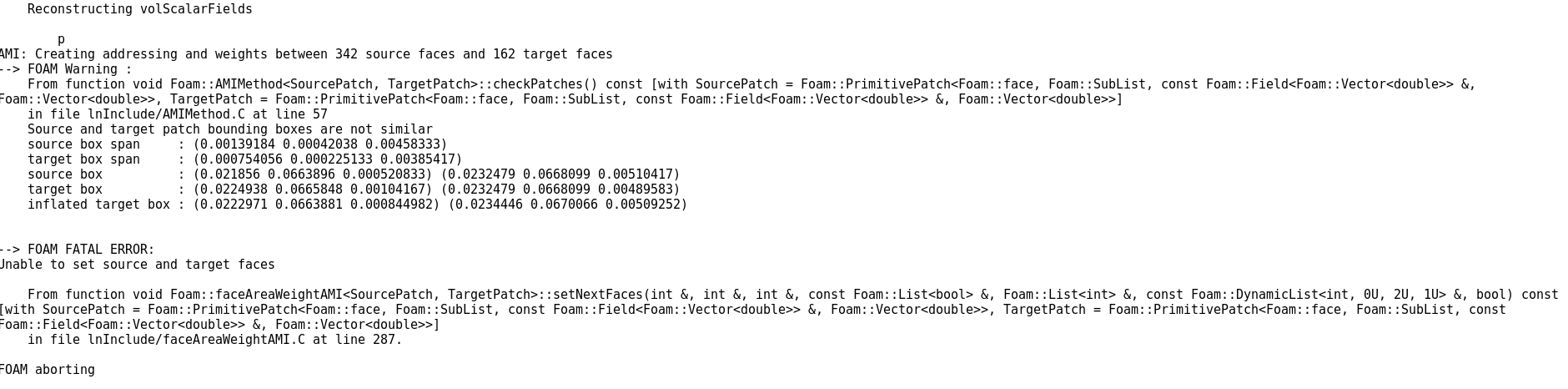
@东岳 请问李老师,我使用cyclicAMI边界条件可以计算,但是当我使用reconstructPar时出现如下错误,这种情况是什么原因呢?
-
请教一下大家,我现在取一小的truncated domain作为LES计算域,初始RANS结果是在20倍的弦长上计算的,截断区域是法向距离为0.5倍弦长,尾迹区域为1倍的弦长,如图所示。
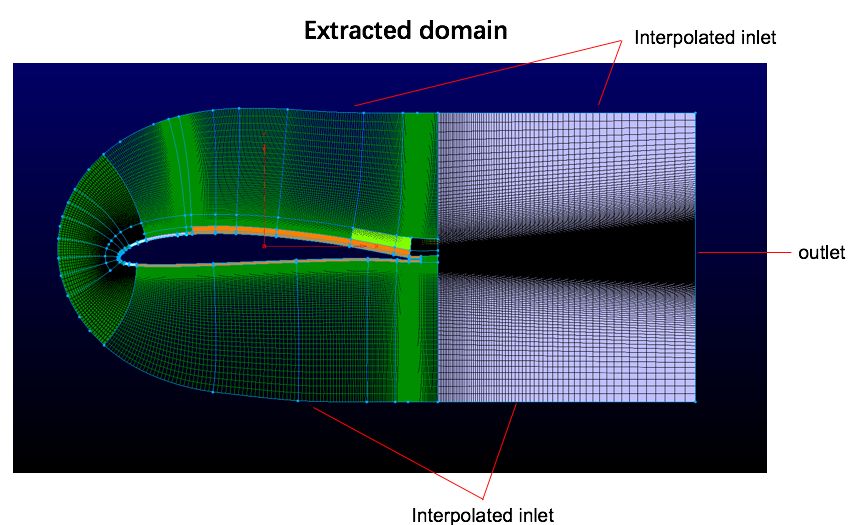
入口设置为RANS结果插值速度和压力,通常OF入口压力都设为ZG,我不清楚这种插值速度设置是否可行,大家如果有知道的是否可以提供一些建议参考?
出口速度设置为advective,请问此时压力该如何设置?我设置为ZG, 计算结果直接从出口开始发散并向内部区域传递。 -
请教一下大家,我用incompressible LES计算带粗糙单元的翼型,远场20倍弦长,计算10个流通时间之间结果趋于收敛并准备进行时间平均,但是计算结果过了10个流通时间后开始发散。是否是边界条件设置问题?
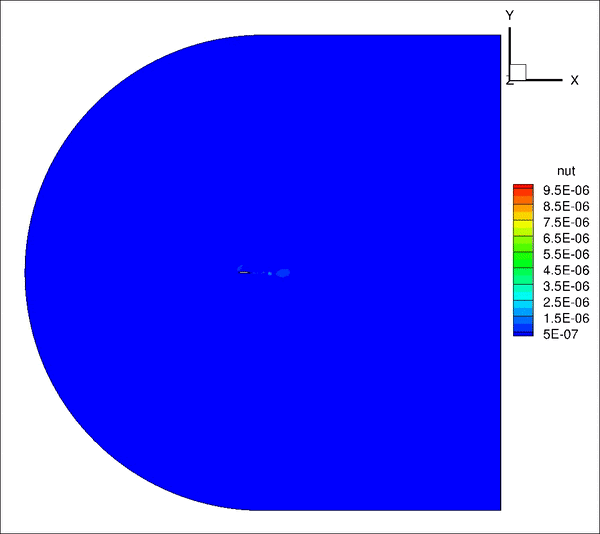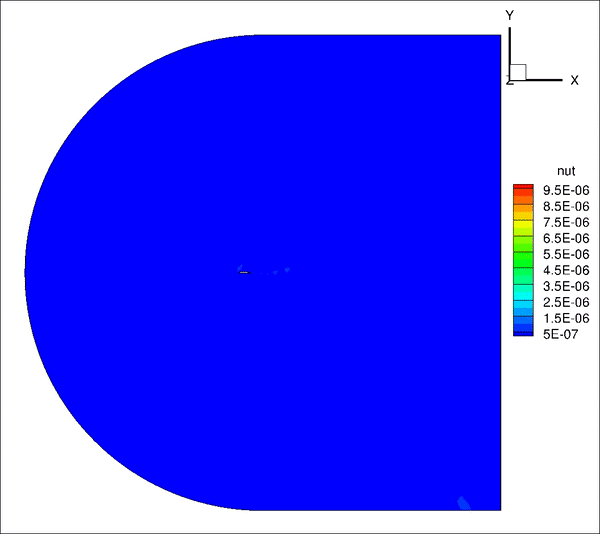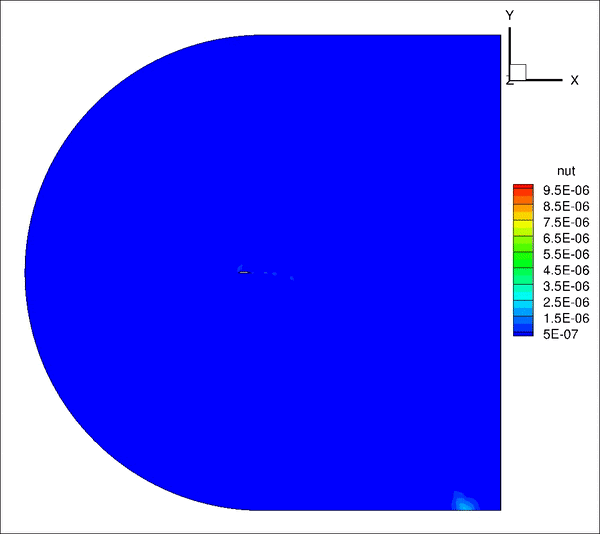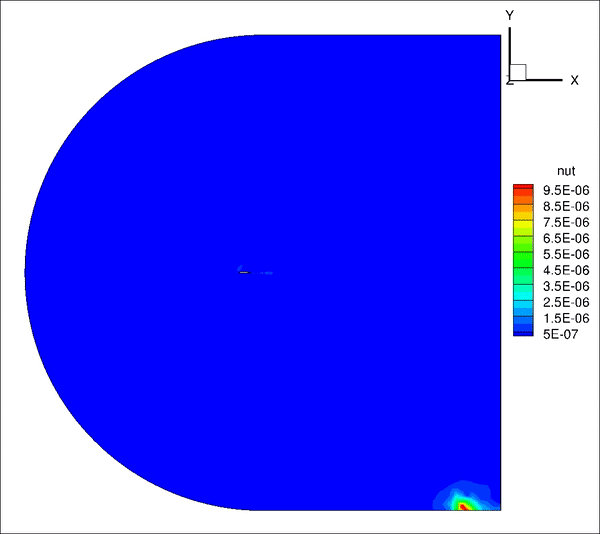
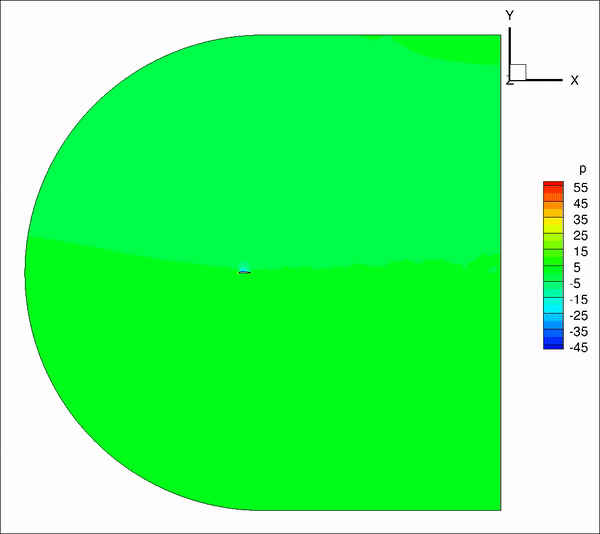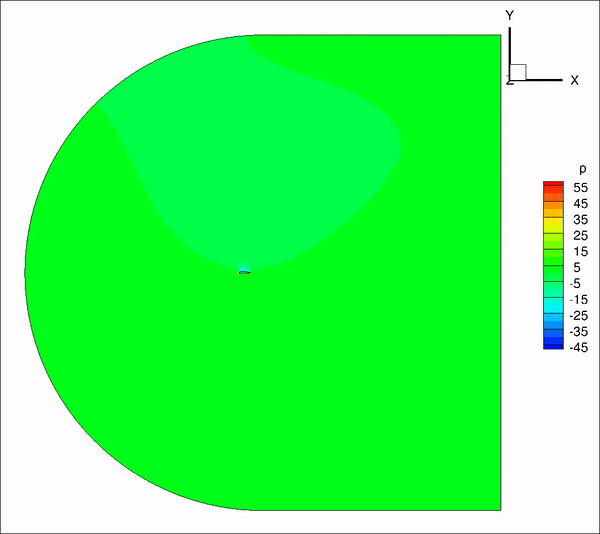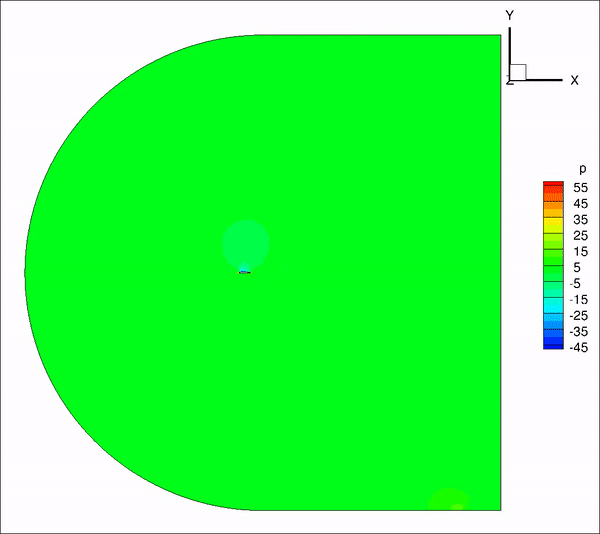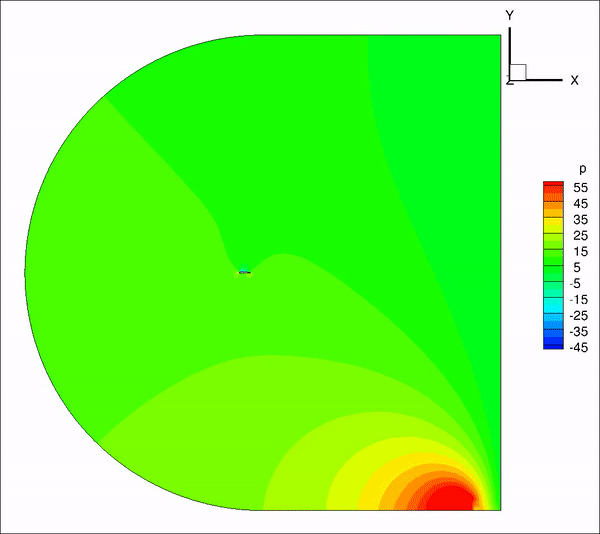
从图上看是下边界出现问题,下面是我的边界条件定义
inlet: U(fixedValue), p(ZG), nut(calculated)
outlet: U(ZG), p(fixedValue 0), nut(ZG)
top&bottom: U(ZG), p(ZG), nut(ZG)除了边界条件,是否还有可能是别的原因造成的?
-
请问大家 我用如下的并行命令
mpirun -np 20 mapFields sourceDirectory -parallelTarget
但是在执行该命令时出现下面的情况

但是map过程没有结束, 请问这种情况如何解决?还是说并行命令有问题? -
@cccrrryyy 请问一下,你在安装到OF4时是直接应用的他们的代码还是修改后才可以在新版本上编译的?
-
@东岳 请问李老师,在使用cyclic AMI时我是直接在如下图里面的createPatch里面定义还是需要使用createBaffels

-
请教大家,我现在有一个混绕机翼的混合网格,但是非结构网格和结构网格在交界面处拓扑不同。Openfoam中有一个cyclic AMI边界条件,但是我看都是用于旋转或是动网格,但是我这网格都不是上面两种情况,那像这种情况该如何给定边界条件?图1是非结构网格在交界面处的网格; 图2 是结构网格在交界面处的网格


-
@bestucan
抱歉,之前在发帖子的时候没注意到这个问题,这个是CFD-online的链接:
https://www.cfd-online.com/Forums/openfoam-installation/71741-pstream-library-error-parallel-mode.html
下面这个是相关命令:
1)echo $FOAM_MPI echo $MPI_ARCH_PATH ls -l $MPI_ARCH_PATH which mpirun2)
change the $WM_PROJECT_DIR/etc/bashrc file: export WM_MPLIB=SYSTEMOPENMPI change the $WM_PROJECT_DIR/etc/config/settings.sh: export FOAM_MPI=openmpi-system -
请教大家,
我目前在学校的HPC cluster上使用OpenFOAM5.0,MPI编译器采用的是INTERMPI。以下是我的Jobscript里需要加载的模块:
module load mpi/intelmpi/2018.1.163 module load intel-studio-2018 module load comp/gcc/6.3.0 module load comp/cmake/3.7.2 module load lib/scotch/6.3.0 source /home/OpenFOAM/OpenFOAM-5.0/etc/bashrc之前采用该脚本文件可以并行计算,但是现在我使用相同的设置,重新再计算原先的算例(网格和计算设置未变),Log文件中显示报错信息:
--> FOAM FATAL ERROR: Trying to use the dummy Pstream library. This dummy library cannot be used in parallel mode From function static bool Foam:UPstream::init(init &, char **&) in file UPstream.C at line 37. FOAM exiting.我之前在CFD-online上查找过相关问题,但是发现问题都是针对较早版本如OpenFOAM231,并且MPI编译器也不同,所以目前还不知道该如何解决该问题。以下是他们的一些解决办法和我目前使用的版本中的设置对比:
1)输入下面的Command诊断MPI设置:
echo $FOAM_MPI echo $MPI_ARCH_PATH ls -l $MPI_ARCH_PATH which mpirun当我输入第一个命令行时,发现$FOAM_MPI为空,并且libPstream.so在lib/dummy中。然后我使用source etc/bashrc,显示:
Warning in /home/OpenFOAM/OpenFOAM-5.0/etc/config.sh/settings: MPI_ROOT not a valid mpt installation directory or ending in a '/'. Please set MPI_ROOT to the mpt installation directory. MPI_ROOT currently set to ' '.- change the $WM_PROJECT_DIR/etc/bashrc file:
export WM_MPLIB=SYSTEMOPENMPI change the $WM_PROJECT_DIR/etc/config/settings.sh: export FOAM_MPI=openmpi-system但是我使用OpenFOAM5.0时,bashrc中:
export WM_MPLIB=INTELMPI而在etc/config,sh/settings文件中并没有export FOAM_MPI, 并且该文件与旧版本变化很大;
请教大家我这种情况该如何解决这个问题呢?急!!!最近被这个搞得很头大。。。
-
@东岳 是的,linux系统
-
请教大家,我现在想在HPC cluster上安装Openfoam 5.0, 目前服务器上已经装有该版本,但是因为我要更改湍流模型,所以需要在当地的用户文件内重新安装该版本。Cluster上已经安装了module Gcc和MPI.
我在网上找到一些教程,不过都是2.x版本,所以可能不完全适用。 下面是主要的几个步骤,我在这里贴出来方便与OF5.0对比
1)
cp /cineca/prod/applications/openfoam/2.3.0-gnu-4.7.2/openmpi--1.6.3--gnu--4.7.2/OF_2.3.0_LOCAL_INSTALL_CINECA_PLX.tar .
tar -xf OF_2.3.0_LOCAL_INSTALL_CINECA_PLX.tar
rm OF_2.3.0_LOCAL_INSTALL_CINECA_PLX.tar
cd OF_2.3.0_LOCAL_INSTALL_CINECA_PLX
ls
OF_2.3.0_LOCAL_INSTALL_CINECA_PLX.sh PATCHES (新版本里并没有该配置文件,只有bashrc)- Execute the script to download, configure and install your local version of OpenFOAM:
./OF_2.3.0_LOCAL_INSTALL_CINECA_PLX.sh
The installation dir, in this case, is located in your $HOME space
FOAM_INST_DIR=$HOME/OpenFOAM
The OpenFOAM environment of the local installation is set in
$HOME/OpenFOAM/OpenFOAM-2.3.x/etc/bashrc - Load the environment of your local installation
module load gnu/4.7.2
module load openmpi/1.6.3--gnu--4.7.2
source $HOME/OpenFOAM/OpenFOAM-2.3.x/etc/bashrc
and you will have
$WM_PROJECT_VERSION=2.3.x
$FOAM_INST_DIR=/plx/userinternal/ispisso0/OpenFOAM
$WM_PROJECT_USER_DIR=/plx/userinternal/ispisso0/OpenFOAM/ispisso0-2.3.x
下面是我在cluster里找到的tar文件,该文件在OF的安装目录里:
5-0.tar.gz backup2.zig backup.zip bashrc OpenFOAM-5.0 (已编译好程序)
我主要有下面几点问题:
1) 这个tar.gz文件包我是否可以直接用它在我的用户文件夹里安装编译?
2)它有一个独立的bashrc文件,这个是否可以直接用来当配置文件?我看了一下里面发现他的WM_COMPILER=Icc,并不是Gcc
3)我是否可以按照上面的OF2.X编译步骤进行?还是有其他的步骤需要我考虑的?谢谢大家!!!最近被这个安装搞得焦头烂额的,希望能有人给我些建议~~~
- Execute the script to download, configure and install your local version of OpenFOAM:
-
@李东岳 有Points文件的
-
@李东岳 是的,我用这个算例试过了,还是一样的问题。

-
@李东岳 是的,显示是这样。我现在用的是OF5.0,我之前以为是我的网格文件有问题,后来我用OF自带的tutorial case,算例用的也是scotch method, 但是我用decomposePar也出现相同的问题。然后我把我自己的网格在OF231中分块就没有问题。所以我在想是不是版本问题。我在网上查找发现OF5的Third-Party需要更新,可能和我现在机子上的不一致
-
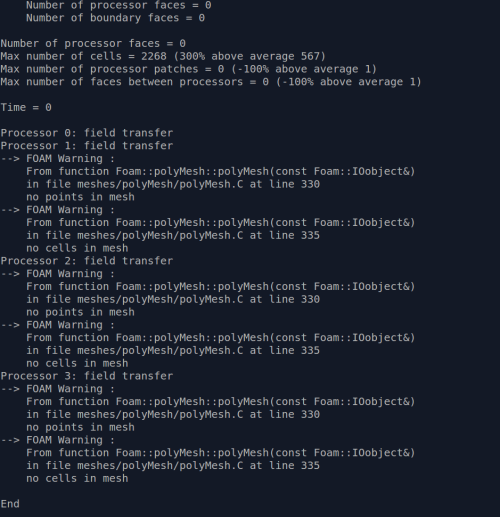
@李东岳 我检查过网格文件 如果我采用simple方法分块可以 但是使用scotch分块就会显示只有一个processor0有网格 其余的processor里显示没有网格
我也不清楚这是为什么 -
decomposePar scotch number of Subdomains 4 Command message: Processor 0: field transfer Processor 1: field transfer --> FOAM Warning : From function Foam::polyMesh::polyMesh(const Foam::IOobject&) in file meshes/polyMesh/polyMesh.C at line 330 no points in mesh --> FOAM Warning : From function Foam::polyMesh::polyMesh(const Foam::IOobject&) in file meshes/polyMesh/polyMesh.C at line 335 no cells in mesh
paraview load state闪退
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
集群上并行测试OpenFOAM,并行效率并没有比单节点提升
pimpleFoam当运行到nOuterCorrectors=3时报错
pimpleFoam当运行到nOuterCorrectors=3时报错
pimpleFoam当运行到nOuterCorrectors=3时报错
pimpleFoam当运行到nOuterCorrectors=3时报错
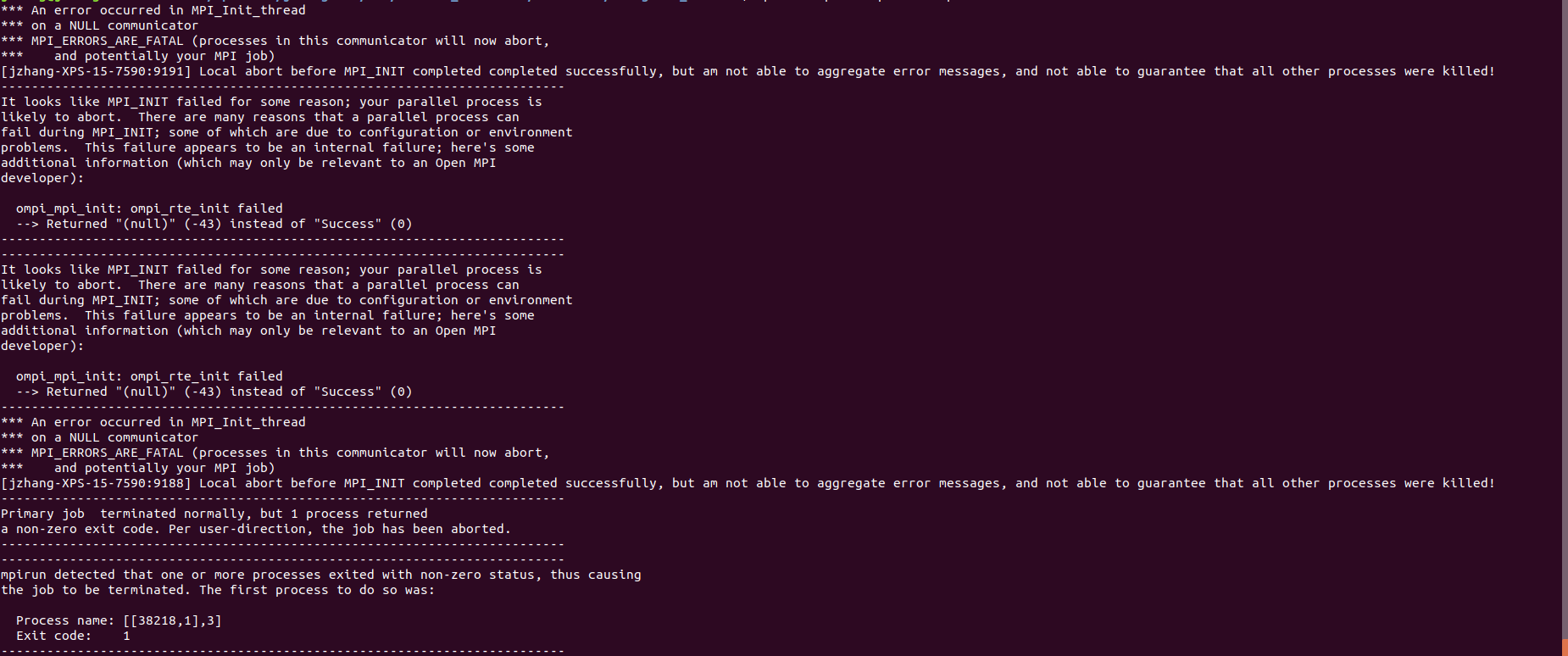
并行计算报错 “an error occurred in MPI_init_thread”
并行计算报错 “an error occurred in MPI_init_thread”
OKS课程买家秀
安装时出现权限不够与找不到命令
交界面处拓扑结构不同,如何定义边界条件
incompressible LES设置advective边界条件问题
问题:incompressible LES计算10个流通时间后开始发散
mapFields并行出错
openfoam添加湍流入口方法?
交界面处拓扑结构不同,如何定义边界条件
交界面处拓扑结构不同,如何定义边界条件
OpenFOAM5.0 HPC cluster计算报错:Pstream library error in parallel mode
OpenFOAM5.0 HPC cluster计算报错:Pstream library error in parallel mode
求助如何在HPC Cluster上安装OF5.0
求助如何在HPC Cluster上安装OF5.0
Openfoam并行分块有问题
Openfoam并行分块有问题
Openfoam并行分块有问题
Openfoam并行分块有问题

Openfoam并行分块有问题
Openfoam并行分块有问题