@SHUKK
你需要 libtorch,这个是C++库,提供了跟 pytorch 一样的功能。也就是说,用pytorch训练的模型,可以做到利用 libtorch 提供的 API 读入到任何 C++ 程序中来用。
针对Open FOAM,这个项目 https://gitlab.com/tmaric/openfoam-ml 可以作为入门参考。
X
xpqiu
@xpqiu
帖子
-
原有的湍流模型加上非线性项雷诺应力的问题 -
原有的湍流模型加上非线性项雷诺应力的问题@SHUKK
你的 g(i) 是用训练好的模型来计算对吧,那么其实你只需要用C++把你计算g(i)相关的代码写出来,写成湍流模型的成员函数,然后再在correctNonLinearStress里面调用这些函数就可以了。虽然g(i)不能写出显式的公式,但是也是代入一些流场变量,然后输出g(i)的数值吧,这样肯定也是可以写出可以调用的函数的。 -
原有的湍流模型加上非线性项雷诺应力的问题@SHUKK
你可以参考一下这个项目:https://github.com/furstj/myTurbulenceModels里面有非线性湍流模型的例子,比如这个 EARSM 模型,https://github.com/furstj/myTurbulenceModels/tree/main/turbulenceModels/RAS/EARSM
你可以在这个 EARSM 模型的基础上来修改,基本上只需要其中的 correctNonlinearStress 函数就可以了。
-
bound 函数的实现方法@李东岳
只是知道用了这个函数就会引起计算错误,但是不确定是不是我其他代码有问题。
希望有大佬路过进来看看这个 bound 函数的实现到底为什么要这样。 -
bound 函数的实现方法不知道为什么这个 bound 函数里面要用到 average 这样的操作。
之所以关心这个问题,是因为这个 average 给我导致一个严重的bug
-
bound 函数的实现方法很多有界变量在计算过程中为了防止数值问题,需要限定下限值,在OpenFOAM中一般都是使用bound 函数,代码见:src/finiteVolume/cfdTools/general/bound/bound.C。然而这个 bound 函数的实现却有些让人摸不着头脑:
Foam::volScalarField& Foam::bound(volScalarField& vsf, const dimensionedScalar& lowerBound) { const scalar minVsf = min(vsf).value(); if (minVsf < lowerBound.value()) { Info<< "bounding " << vsf.name() << ", min: " << minVsf << " max: " << max(vsf).value() << " average: " << gAverage(vsf.primitiveField()) << endl; vsf.primitiveFieldRef() = max ( max ( vsf.primitiveField(), fvc::average(max(vsf, lowerBound))().primitiveField() * pos0(-vsf.primitiveField()) ), lowerBound.value() ); vsf.boundaryFieldRef() = max(vsf.boundaryField(), lowerBound.value()); } return vsf; }一般的想法是,直接把小于 lowerBound 的重置为 lowerBound 就行了。但是 OpenFOAM 的实现是,对于某个变量v,当 0 < v < lowerBound的,令 v=lowBound (与预期一致);当 v < 0 时,
pos0(-vsf.primitiveField())为 1,也就意味着用如下公式重新计算了下限值fvc::average(max(vsf, lowerBound))().primitiveField()这种做法有什么数学上的解释吗?
-
用较小的时间步长,结果反而出问题了@李东岳
参考文献:
Knacke, T. (2013).
Potential effects of Rhie & Chow type interpolations in airframe
noise simulations. In: Schram, C., Dénos, R., Lecomte E. (ed):
Accurate and efficient aeroacoustic prediction approaches for
airframe noise, VKI LS 2013-03. -
IOobject::groupName("omega", alphaRhoPhi.group()) 这句话的意思是?@Chen_hao
当这个模型用于多相流时,IOobject::groupName("omega", alphaRhoPhi.group()) 会变成类似 omega.air 这样的名字。 -
计算一定区域内网格数用 topoSet,把这些区域内的网格提取到 cellSet,提取过程会告诉你网格数量。
-
SHM尖锐直角边界层添加meshQualityControls 部分把 relaxed 里面的质量控制参数再放宽一些。然后 nRelaxedIter 设置为 0。
-
怎样才能取一个局部面作为一个新边界?还可以用 topoSet 结合 createPatch 来实现,不过这样得到的面不一定是精确地 1/2,因为createPatch 只是从已经画好的网格上选一些面来生成一个新边界。
-
怎样把某个截面处的速度分布转移到边界上?@soulx7 参考这个算例:
tutorials/incompressible/pisoFoam/LES/pitzDailyMapped -
Gauss LUST grad(U)和Gauss LUST unlimitedGrad(U)@wg0632
Gauss LUST grad(U) 当中的 grad(U) 对应一个梯度计算格式,会从 gradSchemes 部分取查找。如果 gradSchemes 部分定义了 grad(U) ,则使用该部分的 grad(U) 对应的格式。如果gradSchemes 部分没有定义grad(U) ,则会使用 gradSchemes 部分的 default 对应的格式。如果 default 也没有则报错。所以,Gauss LUST grad(U) 和Gauss LUST unlimitedGrad(U) 的区别取决于 gradSchemes 里面如何定义的 grad(U) 和 unlimitedGrad(U)。
-
三维圆柱绕流升力沿管长分布@BznW
direction 是截取的方向,比如 1 0 0 表示沿着 x 方向分块,nBin 是分块的数量,cumulative yes 表示输出累积结果。
因此,上述图片能达到的效果是,沿着 1 0 0 方向将部件分成 20 等份,然后会分别输出这20份的受力。因为 cumulative 是 yes,所以,第一个输出是第一份的受力,第二个输出是第一份和第二份累积的受力,因此类推。 -
Wray-Agarwal湍流模型A "trip" in the context of computational fluid dynamics (CFD) and the Spalart-Allmaras turbulence model refers to a turbulent trip. Specifically:
A turbulent trip is a device used to trigger a transition from laminar to turbulent flow in a fluid dynamics experiment or simulation. Fluids can flow in either a smooth, laminar state or a chaotic, turbulent state depending on conditions like velocity, viscosity, and surface roughness.
In CFD using the Spalart-Allmaras model, adding a "trip term" attempts to model the effects of an actual physical trip device that would be used in an experimental flow setup. This trip modeling triggers the transition to turbulence in the simulation.
So in the sentence you referenced, the "trip term" refers to an addition made to the Spalart-Allmaras equations that mimics the effect of a physical turbulent trip, forcing a transition from laminar to turbulent modeling. This trip modeling can be important to accurately replicating real experimental conditions in the CFD simulation.
-
mpirun并行显示运算中,但是实际log文件无输出@洱聿 集群如果使用作业调度软件来提交作业的话,应该生成日志文件(类似 xxx.out and/or xxx.err),里面可能有什么报错信息。
-
关于并行中的reduce函数@Tens 在 关于并行中的reduce函数 中说:
List<scalar> np(20,0.0); for (label i=0;i<20;i++) { np[i] += xxxx; //每个时间步累加 reduce(np[i], sumOp<scalar>()); }这段代码如果以比如 6 核运行,那么如果先不看 reduce 这句,则是这6个核各自都会创建一个长度为 20 的list,然后执行这个循环,最终得到的结果是每个核各自有一份自己的 np 值,如果xxxx是常数,则每个核的np值都一样,如果xxxx是一个不同核数取值不一样的数,则每个核中最终得到的 np 值不一样。
reduce(np[i], sumOp<scalar>()) 的作用是将每个核的 np[i] 全都累加起来(因为这里的第二个参数是sumOp,表示加和),然后将累加之后得到的值再分发给所有核,最终每个核中的 np 的值都一样。
所以加上reduce之后导致的结果就是,最终得到的每个核中的 np的值都一样,但是 np 的值显然会受核数影响。
举例说,假设 xxxx 是常数,等于10 ,则 单核运行时,np 的每个分量都是10,如果6核运行,则最终得到np 的每个分量都是 60。因为reduce之前,每个核的 np 都是10,reduce 的时候,将每个核的值累加起来,得到60。以此类推,核数越多,得到的 np 值越大。
-
双流体方法颗粒堆积模拟可能是J-J 摩擦应力模型的问题。
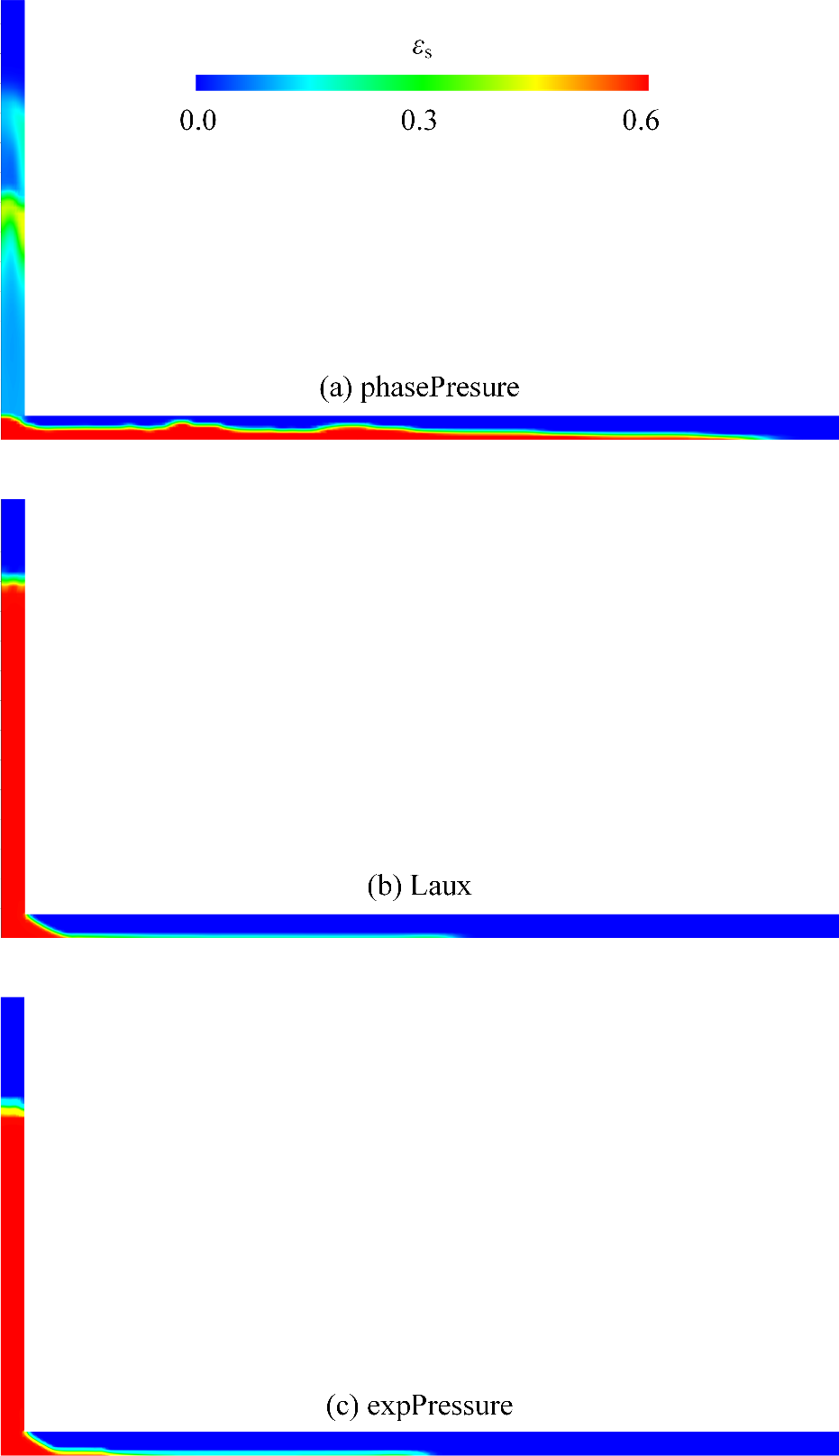
上面图里面第一个是不考虑摩擦应力的结果,下面两个是考虑摩擦应力的结果。摩擦应力模型用的是 Laux,对应参考文献是:
A. Nikolopoulos, N. Nikolopoulos, N. Varveris, S. Karellas, P. Grammelis, and E.
Kakaras, Investigation of proper modeling of very dense granular flows in the
recirculation system of CFBs. Particuology, 2012, 10(6):699-709 -
双流体方法颗粒堆积模拟@李东岳
对,摩擦应力(frictional stress)很重要。加上摩擦应力才能在双流体模型中模拟出来堆积角。 -
算例topoSet、refineMesh后,无法decomposePar@hy1112006
哦,你的 refineMeshDict 里面需要一个 cellSet 来定义需要refine 的网格。这个 cellSet 也只是用来起这个作用吧。
所以,你需要在 refineMesh 之前,先 topoSet 把 cellSet 生成出来,然后 refineMesh
但是,在 decomposePar 的时候要排除对 cellSet 进行 decompose,因为我上一条回复说的原因。可以给 decomposePar 加一个选项,-noSets,这样在 decomposePar 的时候就不读取 cellSet 了,也就不会再触发你主楼遇到的错误了。