OpenFOAM并行计算不同进程数下获取场的积分值不同
-
如题,我尝试使用如下方法获取alpha2在整个计算域上的积分值:
scalar globalAlphaV = fvc::domainIntegrate(alpha2).value();但令我不解的是,当我分别尝试用单核、双核、4核进行计算,得到的globalAlphaV的结果却不同,这是为什么?
单核:t value 0.00120482 0 0.00265769 6.08302e-07 0.00439595 1.09555e-06 0.00647429 1.2463e-06 0.0089355 1.33113e-06 0.0118731 1.38863e-06 0.0153981 1.38907e-06 0.0196282 1.86323e-06 0.0246515 2.1633e-06 0.0304475 2.7274e-06 0.0374028 3.00516e-06 0.0452274 3.34962e-06双核:
t value 0.00120482 0 0.00265769 2.03837e-06 0.00439595 1.92813e-06 0.00647429 2.09112e-06 0.0089355 2.13259e-06 0.0118731 2.12188e-06 0.0153981 2.22201e-06 0.0196282 2.49843e-06 0.0246515 2.58062e-06 0.0304475 2.77294e-06 0.0374028 2.95374e-06 0.0452274 3.17708e-06四核:
t value 0.00120482 0 0.00265769 2.96666e-07 0.00439595 1.55379e-07 0.00647429 2.30832e-07 0.0089355 4.49495e-07 0.0118731 5.51889e-07 0.0153981 6.1708e-07 0.0196282 6.46681e-07 0.0246515 7.35564e-07 0.0304475 7.13041e-07 0.0374028 8.00214e-07 0.0452274 8.97498e-07 -
单核应该是对的。多核执行只是限制在每一个核了。你可以测试下:
scalar meshVolume(0); forAll(mesh.V(),cellI) { meshVolume += mesh.V()[cellI]; } Pout << "Mesh volume on this processor: " << meshVolume << endl; reduce(meshVolume, sumOp<scalar>()); Info << "Total mesh volume on all processors: " << meshVolume << endl; -
@李东岳 在 OpenFOAM并行计算不同进程数下获取场的积分值不同 中说:
scalar meshVolume(0);
forAll(mesh.V(),cellI)
{
meshVolume += mesh.V()[cellI];
}Pout << "Mesh volume on this processor: " << meshVolume << endl;
reduce(meshVolume, sumOp<scalar>());
Info << "Total mesh volume on all processors: " << meshVolume << endl;老师,您的代码我测试了,结果如下:
四核:[0] Mesh volume on this processor: 829.44 [1] Mesh volume on this processor: 1320.32 [2] Mesh volume on this processor: 718.72 [3] Mesh volume on this processor: 1499.52 Total mesh volume on all processors: 4368双核:
[0] Mesh volume on this processor: 2177.28 [1] Mesh volume on this processor: 2190.72 Total mesh volume on all processors: 4368但是domainIntegrate这个函数的作用不就是为了整合各个计算域之间的结果吗:
domainIntegrate(phi) = gSum(fvc::volumeIntegrate(phi));同时我测试了另一个网格,用24核和36核算了一段时间后发现两者相同时间下差距较小,感觉应该不是某一个核心的结果,而更像是误差?
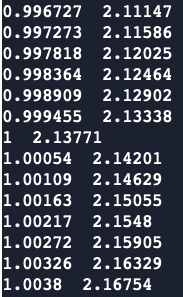
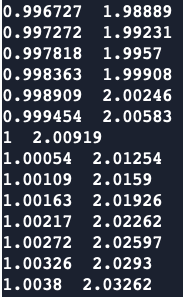
同时还想请教一个问题,就在刚刚我发现前后两次不改任何设置的情况下,进行decompose操作(scotch方法)得到计算域划分结果竟然是不同的:
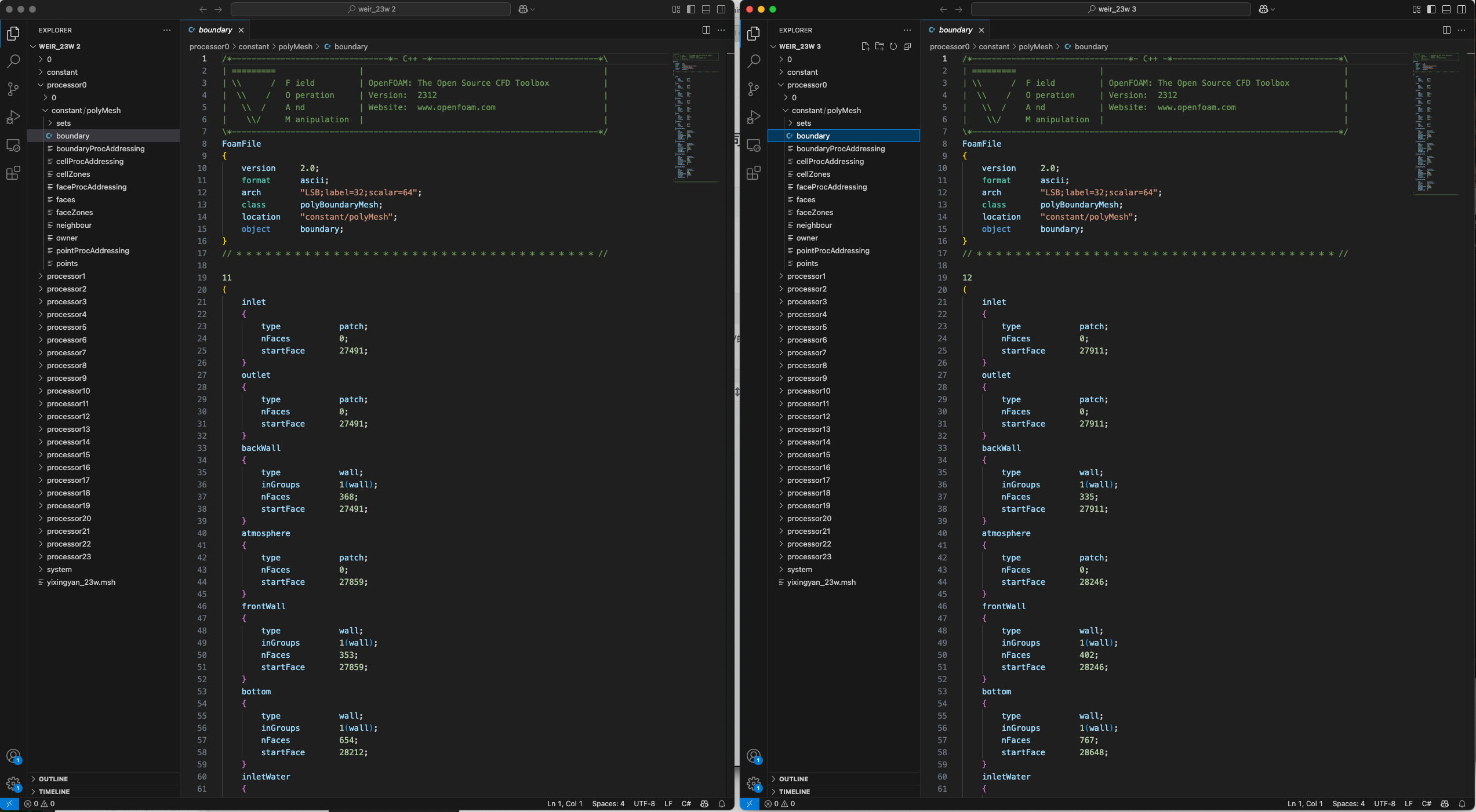
进而导致一个计算正常进行,一个计算一段时间就发散了,这是什么原因?
