@李东岳 在 LES计算中入口 湍流度/脉动速度 如何设置和控制? 中说:
后续的有关LES入口的可以参考这个帖子 LES定义入口速度的问题(DSRFG方法)
用的动态拉格朗日模型
@aiweimo 大佬你当时为什么用这个湍流模型?有特殊的原因么
李老师,没有特殊原因,当时用的是第三方的SOWFA代码包,刚好用了这个模型,没有对亚格子模型进行研究过
@李东岳 在 LES计算中入口 湍流度/脉动速度 如何设置和控制? 中说:
后续的有关LES入口的可以参考这个帖子 LES定义入口速度的问题(DSRFG方法)
用的动态拉格朗日模型
@aiweimo 大佬你当时为什么用这个湍流模型?有特殊的原因么
李老师,没有特殊原因,当时用的是第三方的SOWFA代码包,刚好用了这个模型,没有对亚格子模型进行研究过
@李东岳 在 2D欧拉拉格朗日计算 中说:
几天要推送一个2D/3D模拟的文章,可以关注下
@李东岳 李老师,公众号找了一圈,好像没找到,这个公众号文章链接可以发一下么?最近同学投了一篇文章,是基于欧拉-拉格朗日方法的,做的沙尘障碍物绕流2D研究。一个审稿人意见是他不接受2D Model,并且明确表明如果下一稿还是2D Model的话不用给他审直接拒绝。我就想到之前公众号好像有一篇推文。但是搜不到了。
@xpqiu gzt200361@163.com
非常感谢
@hy1112006 在网上找了很久,发现这本书的free版本内容不全,必须购买完整版才能使用。请问您有这本书的完整版本么?
@aiweimo 在 ParaView并行体渲染速度跟工作站硬件配置的关系? 中说:
@xpqiu 我查看了,已经安装了这个驱动,是正常显示我的显卡型号的。我后面想用NVIDIA Index插件,所以之前专门打了驱动的。
我后面搞了一下,发现是我的ParaView版本弄错了,我下的不是MPI版本,我自己重新下了一个MPI版本ParaView,打开渲染发现CPU和显卡都能多占用20%了。我猜有效果。然后我对于ParaView并行运行还是有一些疑问:如果通过MPI方式调用ParaView处理数据,OpenFOAM算例结果必须是分区(processor0, processor1...)的么?
我现在是reconstruction之后的,合成的数据。调用MPI读入网格后提示:
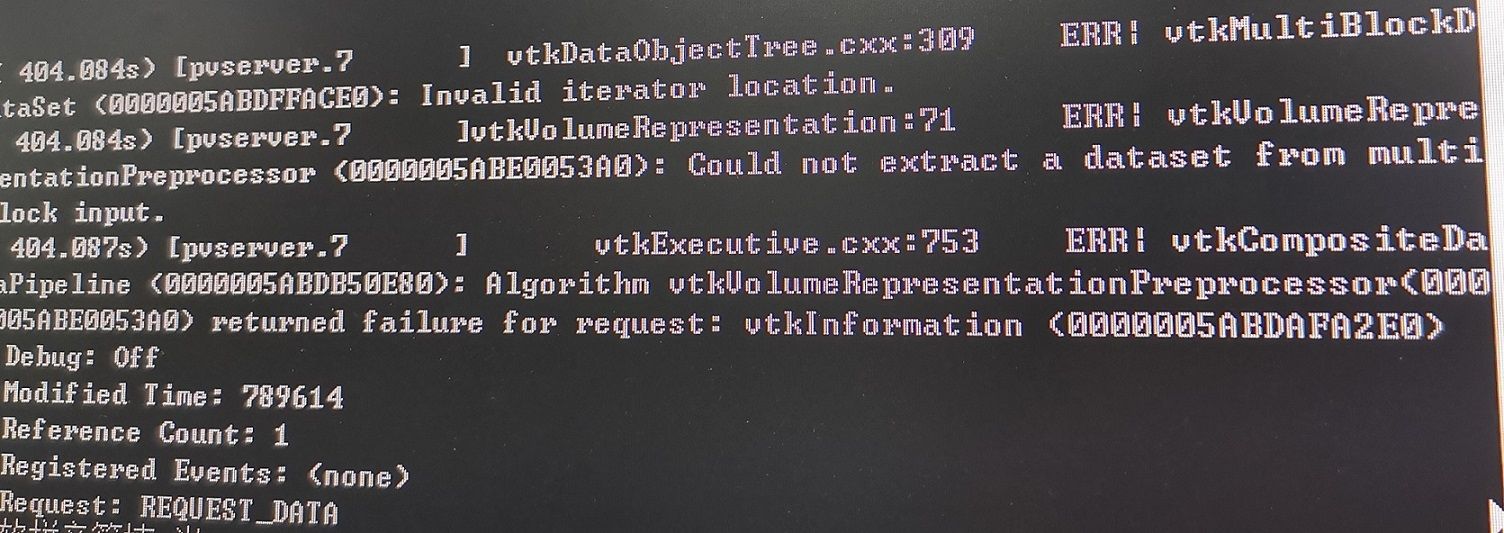
vtkMultiBlockDataSet: Structure does not match. You must use CopyStructure before calling this method.
然后CMD也提示:vtkMultiBlockDataSet、vtkVolumeRepresentationPreprocessor和vtkCompositeDatapipeLine出错
对一个670万网格的算例结果做体渲染(Volume Rendering),这个ParaView的体渲染速度快慢跟CPU主频关系大?还是跟CPU核数多少关系大?还是跟内存、显存、硬盘转速关系大呢?
我自己做了一个测试,运行mpiexec -np 20 pvserver后打开ParaView连接到本地端(这算不算并行运行了ParaView?)之后在渲染的时候,发现一动视角就很卡、显示正在渲染,渲染的过程大约有2个步骤:UnstructureGridVolumeRepresentation 和 OpenGLProjectedTetrahedraMapper
但是看CPU、内存、显卡也没有利用率很高的样子,显卡利用率2%,CPU虽然开了20核,但是利用率23%左右;内存占用50%多,但由于还有其他同学读了一个网格没关闭,所以这50%里面我的估计最多占10%。看知乎说渲染费显卡,但我这个显卡似乎没怎么用,到底ParaView 体渲染的速度耗费的是什么性能?
这台工作站主要用来流畅地后处理、体渲染,基本不做大型计算,如果要升级配置,应该升级CPU主频?升级内存频率?还是换固态硬盘?亦或是换高级专业显卡比较好呢?
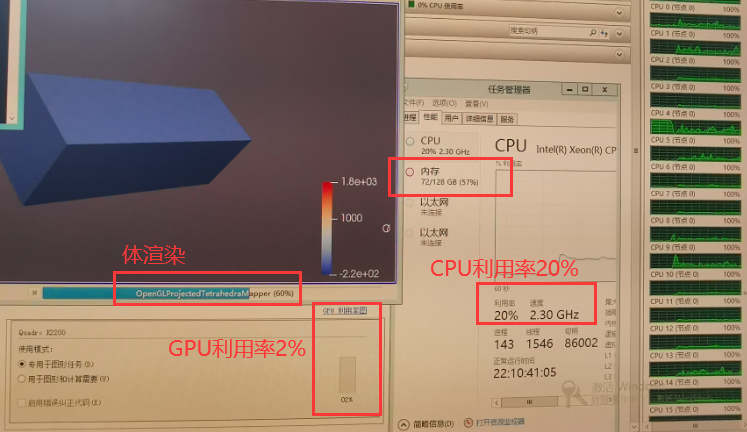
末尾附上 工作站配置(DELL T630),几年前买的一台工作站,现在主要用于后处理了。
CPU: E5-2650 v3 2.3 GHz十核处理器 X 2片 (共计20核)
内存: 镁光 DDR4 2133MHz 16GB X 8片 (组成四通道,共128GB)
显卡: Nvidia Quadro K2200 GDDR5 4GB
主硬盘: 三星250G 5400转/分,数据硬盘: 西数2T 7200转/分
系统运行在主硬盘,软件安装在数据硬盘,所读取的数据也在数据硬盘。


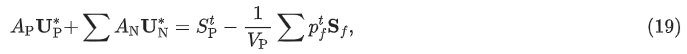
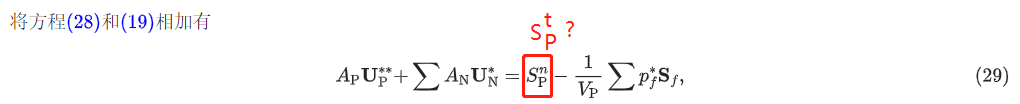
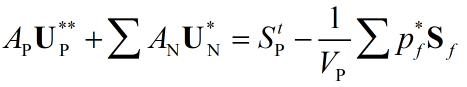
 多谢,我一定尝试一下告知结果。后来给老师干活儿忘记了
多谢,我一定尝试一下告知结果。后来给老师干活儿忘记了







