OpenFOAM libtorch tutorial step by step
-
LibTorch can be used in the environment of OpenFOAM. Instead of using PyTorch, using libtorch seems to be straightforward in the environment of OpenFOAM since both of them are written in C++. In this tutorial, the programming of LibTorch and OpenFOAM is demonstrated step by step. It was tested by OpenFOAM-7, 8, 9, 10, 11, v2306.
-
Download libtorch: https://download.pytorch.org/libtorch/cpu/libtorch-cxx11-abi-shared-with-deps-2.0.0%2Bcpu.zip
-
unzip it(in my case, I put it under:
~/OpenFOAM):unzip libtorch-cxx11-abi-shared-with-deps-2.0.0+cpu.zipafter its done, rename it as
libtorch -
download this test case, torchFoam.tar.xz, unzip it anywhere you want. (In this solver, you will see how to set
Make/optionsin order to let OpenFOAM find libtorch) -
wmaketorchFoam -
Open
.bashrcfile, add the following:export LD_LIBRARY_PATH=~/OpenFOAM/libtorch/lib:$LD_LIBRARY_PATHthen
source ~/.bashrc -
run
torchFoam, output:dyfluid@dyfluid-virtual-machine:~$ torchFoam 0.2870 0.5473 0.5788 0.5582 0.2020 0.7702 [ CPUFloatType{2,3} ]
-
-
-
东岳老师您好,我正在做基于伴随的流热力拓扑优化,想用神经网络预测流体伴随方程解,在配置您说的这个libtorch时编译torchFoam失败了(我的环境变量都按您说的配置好了),我用的是您配置的openfoam5x的虚拟机,请问of版本不兼容吗?您用的是哪个版本of配置的呢?
-
@1064168551 
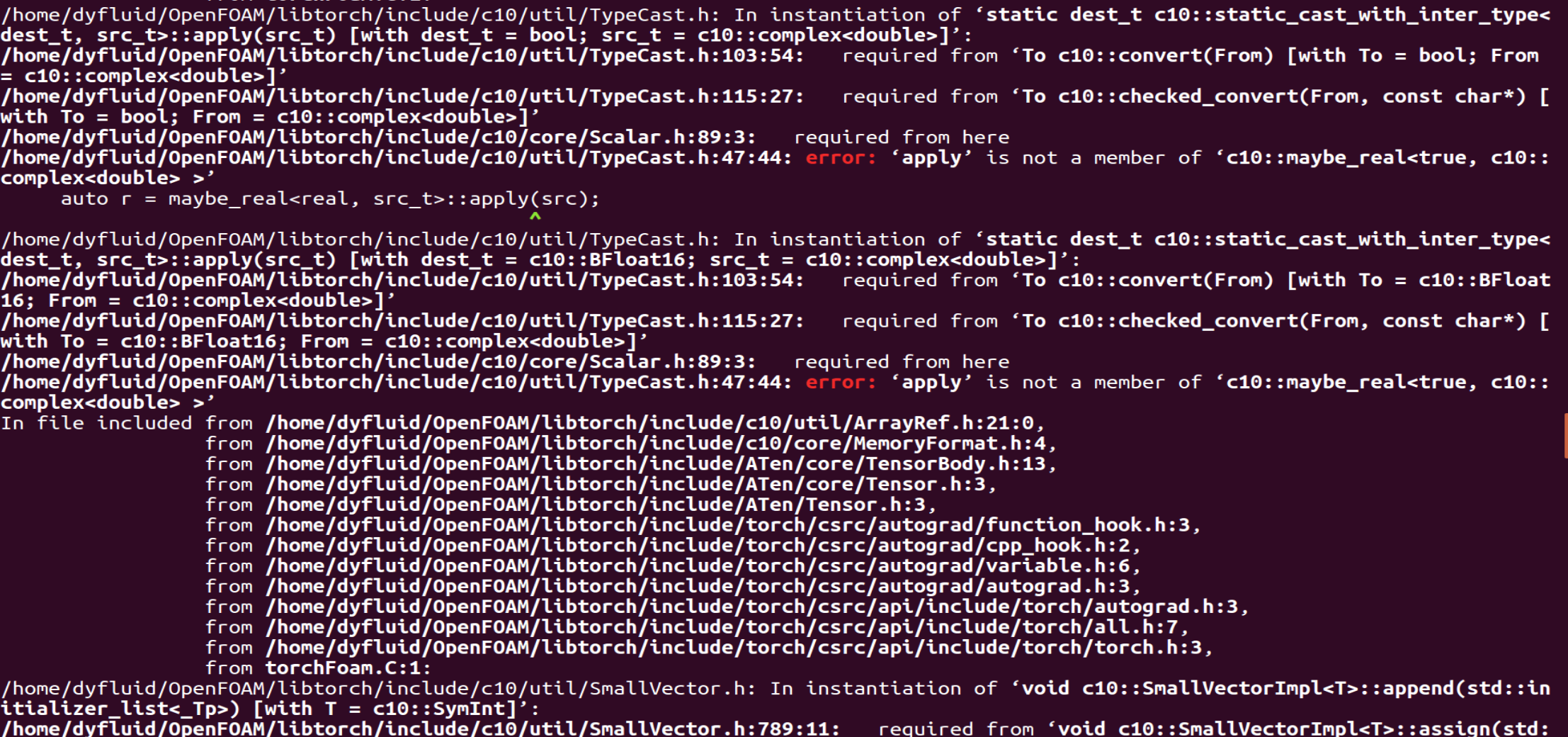 81973254-44c95d02-bafe-4b04-8ecb-10603fb0e805-image.png) 这里截了下部分报错信息
81973254-44c95d02-bafe-4b04-8ecb-10603fb0e805-image.png) 这里截了下部分报错信息 -
@1064168551 我刚又编译了一个新的程序,没问题。你应该是版本问题。
-
@李东岳 在 OpenFOAM外挂libtorch 中说:
http://dyfluid.com/download.html 我这面有全系列的,里面gcc也可以切换。
你用你的老版本也行,老版本要更新gcc。
不管咋的你可以试试,有问题反馈我我协助谢谢东岳老师,我的伴随拓扑优化是用老版本of写的,我试着更新gcc后编译一下,感谢感谢
-
CFD算法编程课: http://dyfluid.com/class.html
需要帮助debug算例的看这个 https://cfd-china.com/topic/8018
-
-
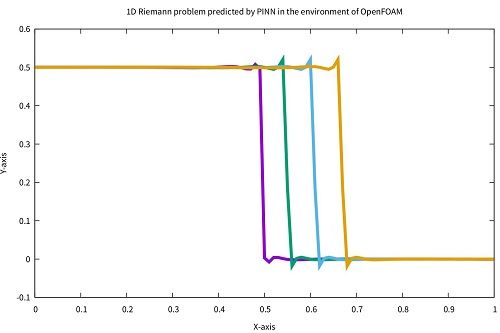
这是个我写的求解1D对流方程的代码。PINN方法。可以在openfoam下执行。
#include <torch/torch.h> #include "net.H" int main() { int iter = 1; int IterationNum = 1000; // Computational domain double dx = 0.1; double dt = 0.1; torch::Tensor x = torch::arange(-1, 1 + dx, dx); torch::Tensor t = torch::arange(0, 1 + dt, dt); torch::Tensor meshAndTime = torch::stack(torch::meshgrid({x, t})).reshape({2, -1}).transpose(0, 1); torch::DeviceType device = torch::kCPU; torch::nn::MSELoss criterion = torch::nn::MSELoss(); std::shared_ptr<NN> model = std::make_shared<NN>(); model->to(device); std::shared_ptr<torch::optim::Adam> adam = std::make_shared<torch::optim::Adam>(model->parameters()); torch::Tensor inlet = torch::stack ( torch::meshgrid({x.index({0}), t}) ).reshape({2, -1}).transpose(0, 1); torch::Tensor outlet = torch::stack ( torch::meshgrid({x.index({-1}), t}) ).reshape({2, -1}).transpose(0, 1); torch::Tensor ic = torch::stack ( torch::meshgrid({x, t.index({0})}) ).reshape({2, -1}).transpose(0, 1); torch::Tensor icbc = torch::cat({outlet, inlet, ic}); torch::Tensor U_inlet = torch::full({11}, 0.5); torch::Tensor U_outlet = torch::zeros(outlet.size(0)); torch::Tensor UiniLeft = torch::full({11}, 0.5); torch::Tensor UiniRight = torch::full({10}, 0.); //torch::Tensor U_ic = torch::cat({UiniLeft, UiniRight}); torch::Tensor U_ic = torch::tensor ( {0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.4,0.3,0.2,0.1,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.} ); torch::Tensor U_icbc = torch::cat({U_outlet, U_inlet, U_ic}).unsqueeze(1); meshAndTime = meshAndTime.to(device); U_icbc = U_icbc.to(device); icbc = icbc.to(device); meshAndTime.requires_grad_(true); model->train(); // Iteration for (int i = 0; i < IterationNum; i++) { adam->zero_grad(); torch::Tensor U_icbcPred = model->forward(icbc); torch::Tensor loss_data = criterion(U_icbcPred, U_icbc); torch::Tensor UIter = model->forward(meshAndTime); torch::Tensor dudxt = torch::autograd::grad ( {UIter}, {meshAndTime}, {torch::ones_like(UIter)}, true, true )[0]; torch::Tensor dudt = dudxt.index({torch::indexing::Slice(), 1}); torch::Tensor dudx = dudxt.index({torch::indexing::Slice(), 0}); torch::Tensor loss_pde = criterion(dudt, -0.3*dudx); torch::Tensor loss = loss_pde + loss_data; loss.backward(); adam->step(); if (iter % 100 == 0) { std::cout << iter << " " << loss.item<double>() << std::endl; } iter++; } // output results torch::Tensor Ufinal = model->forward(meshAndTime); Ufinal = Ufinal.reshape({(int)(2/dx) + 1, (int)(1/dt) + 1}); std::ofstream file("U"); for (int i = 0; i < Ufinal.size(0); i++) { for (int j = 0; j < Ufinal.size(1); j++) { file << Ufinal[i][j].item<float>() << " "; } file << "\n"; } file.close(); std::cout<< "Done!" << std::endl; return 0; }上面给的是光滑的数据。在纯的黎曼问题的时候,有震荡如下图。感觉需要附加监督点
-
net.H
#include <torch/torch.h> class NN : public torch::nn::Module { torch::nn::Sequential net_; public: NN(); torch::Tensor forward(torch::Tensor x); };net.C
/*---------------------------------------------------------------------------*\ ========= | \\ / F ield | OpenFOAM: The Open Source CFD Toolbox \\ / O peration | Website: https://openfoam.org \\ / A nd | Copyright (C) 2022-2023 OpenFOAM Foundation \\/ M anipulation | ------------------------------------------------------------------------------- License This file is part of OpenFOAM. OpenFOAM is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version. OpenFOAM is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. You should have received a copy of the GNU General Public License along with OpenFOAM. If not, see <http://www.gnu.org/licenses/>. Class See also SourceFiles \*---------------------------------------------------------------------------*/ #include "net.H" NN::NN() { net_ = register_module ( "net", torch::nn::Sequential ( torch::nn::Linear(2,20), torch::nn::ReLU(), torch::nn::Linear(20,30), torch::nn::ReLU(), torch::nn::Linear(30,30), torch::nn::ReLU(), torch::nn::Linear(30,20), torch::nn::ReLU(), torch::nn::Linear(20,20), torch::nn::ReLU(), torch::nn::Linear(20,1) ) ); }; torch::Tensor NN::forward(torch::Tensor x) { return net_->forward(x); }这个要编译成库,挂到PINNFoam上面
-
更新一段代码,简单的做个一维拟合。蓝线是训练数据。黄点灰点是预测值。
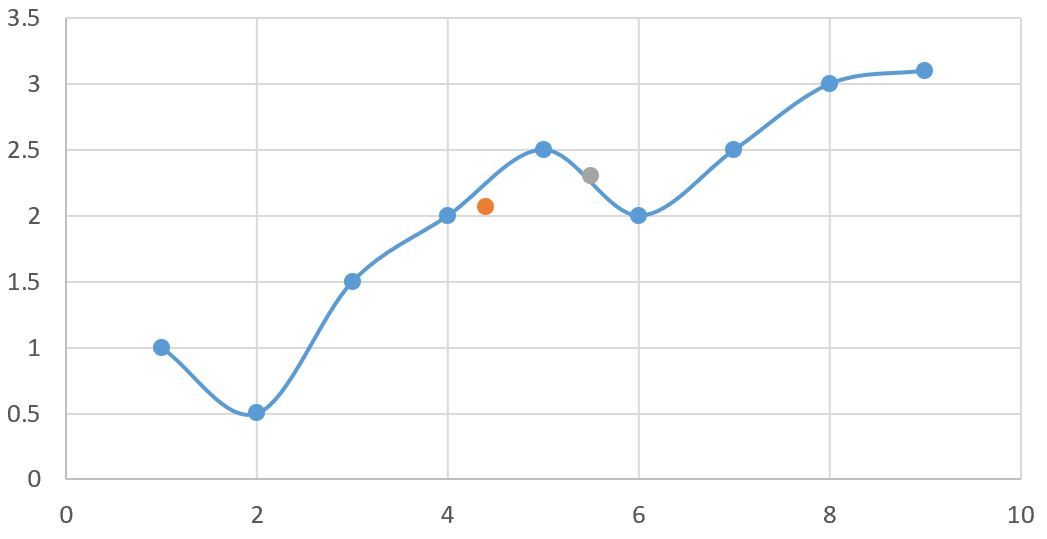
#include <torch/torch.h> typedef torch::Tensor TT; class NN : public torch::nn::Module { torch::nn::Sequential net_; public: NN() { net_ = register_module ( "net", torch::nn::Sequential ( torch::nn::Linear(1,20), torch::nn::ReLU(), torch::nn::Linear(20,30), torch::nn::ReLU(), torch::nn::Linear(30,30), torch::nn::ReLU(), torch::nn::Linear(30,30), torch::nn::ReLU(), torch::nn::Linear(30,1) ) ); } torch::Tensor forward(torch::Tensor x) { return net_->forward(x); } }; int main() { torch::manual_seed(30); TT X = torch::tensor({1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0}).reshape({-1, 1}); TT Y = torch::tensor({1.0, 0.5, 1.5, 2.0, 2.5, 2.0, 2.5, 3.0, 3.1}).reshape({-1, 1}); std::shared_ptr<NN> model = std::make_shared<NN>(); torch::nn::MSELoss criterion = torch::nn::MSELoss(); torch::optim::Adam adam(model->parameters(), torch::optim::AdamOptions(0.01)); const size_t num_epochs = 1000; for (size_t epoch = 0; epoch < num_epochs; ++epoch) { TT output = model->forward(X); TT loss = criterion(output, Y); adam.zero_grad(); loss.backward(); adam.step(); if ((epoch + 1) % 100 == 0) { std::cout << "Loss: " << loss.item<float>() << std::endl; } } //model->eval(); TT test = torch::tensor({4.4, 5.5}).reshape({-1, 1}); TT predic = model->forward(test); std::cout<< "prediction is " << predic << std::endl; return 0; }单变量对多变量变种:
#include <torch/torch.h> typedef torch::Tensor TT; class NN : public torch::nn::Module { torch::nn::Sequential net_; public: NN() { net_ = register_module ( "net", torch::nn::Sequential ( torch::nn::Linear(1,20), torch::nn::ReLU(), torch::nn::Linear(20,30), torch::nn::ReLU(), torch::nn::Linear(30,30), torch::nn::ReLU(), torch::nn::Linear(30,30), torch::nn::ReLU(), torch::nn::Linear(30,2) ) ); } torch::Tensor forward(torch::Tensor x) { return net_->forward(x); } }; int main() { torch::manual_seed(30); TT X = torch::tensor({1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0}).reshape({-1, 1}); TT Y = torch::tensor({{1.0, 1.0}, {0.5, 0.5}, {1.5, 1.5}, {2.0, 2.0}, {2.5, 2.5}, {2.0, 2.0}, {2.5, 2.5}, {3.0, 3.0}, {3.1, 3.1}}).reshape({-1, 2}); std::shared_ptr<NN> model = std::make_shared<NN>(); torch::nn::MSELoss criterion = torch::nn::MSELoss(); torch::optim::Adam adam(model->parameters(), torch::optim::AdamOptions(0.01)); const size_t num_epochs = 1000; for (size_t epoch = 0; epoch < num_epochs; ++epoch) { TT output = model->forward(X); TT loss = criterion(output, Y); adam.zero_grad(); loss.backward(); adam.step(); if ((epoch + 1) % 100 == 0) { std::cout << "Loss: " << loss.item<float>() << std::endl; } } //model->eval(); TT test = torch::tensor({4.4, 5.5}).reshape({-1, 1}); TT predic = model->forward(test); std::cout<< "prediction is " << predic << std::endl; return 0; } -
下面这个代码是个正儿八经的监督学习。下图左边是OpenFOAM算的,右边是OpenFOAM环境下libtorch训练的。

#include <torch/torch.h> #include "argList.H" #include "solver.H" #define SIZE 64 typedef torch::Tensor TT; class NN : public torch::nn::Module { torch::nn::Sequential net_; public: NN() { net_ = register_module ( "net", torch::nn::Sequential ( torch::nn::Linear(1,20), torch::nn::ReLU(), torch::nn::Linear(20,30), torch::nn::ReLU(), torch::nn::Linear(30,30), torch::nn::ReLU(), torch::nn::Linear(30,30), torch::nn::ReLU(), torch::nn::Linear(30,SIZE) ) ); } torch::Tensor forward(torch::Tensor x) { return net_->forward(x); } }; using namespace Foam; int main(int argc, char *argv[]) { #include "setRootCase.H" #include "createTime.H" #include "createMesh.H" #include "createFields.H" scalarField P0internal = P[0].primitiveField(); scalarField P1internal = P[1].primitiveField(); float* P0array = new float[SIZE]; float* P1array = new float[SIZE]; for (int i = 0; i < SIZE; i++) { P0array[i] = P0internal[i]; P1array[i] = P1internal[i]; } TT P0label = torch::from_blob(P0array, SIZE, torch::kFloat32).clone(); TT P1label = torch::from_blob(P1array, SIZE, torch::kFloat32).clone(); delete [] P0array; delete [] P1array; TT X = torch::tensor({1.0, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8}).reshape({-1, 1}); torch::Tensor Y = torch::cat ( { P0label.unsqueeze(0), P1label.unsqueeze(0) } ); //std::cout<< "Y = " << Y << std::endl; std::shared_ptr<NN> model = std::make_shared<NN>(); torch::nn::MSELoss criterion = torch::nn::MSELoss(); torch::optim::Adam adam(model->parameters(), torch::optim::AdamOptions(0.001)); for (int epoch = 0; epoch < 1500; epoch++) { //Info<< "epoch = " << epoch << nl; TT output = model->forward(X); TT loss = criterion(output, Y); adam.zero_grad(); loss.backward(); adam.step(); if ((epoch + 1) % 100 == 0) { std::cout << "Loss: " << loss.item<float>() << std::endl; } } TT test = torch::tensor({2.0}).reshape({-1, 1}); TT predic = model->forward(test); std::cout<< "prediction is " << predic.reshape({-1,1}) << std::endl; return 0; } -
