OpenFOAM libtorch tutorial step by step
-
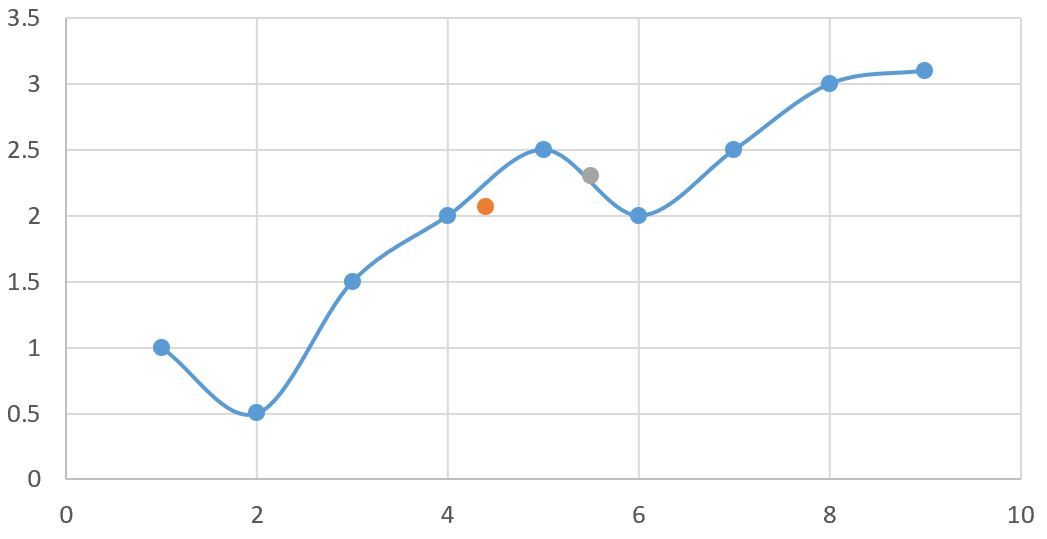
更新一段代码,简单的做个一维拟合。蓝线是训练数据。黄点灰点是预测值。
#include <torch/torch.h> typedef torch::Tensor TT; class NN : public torch::nn::Module { torch::nn::Sequential net_; public: NN() { net_ = register_module ( "net", torch::nn::Sequential ( torch::nn::Linear(1,20), torch::nn::ReLU(), torch::nn::Linear(20,30), torch::nn::ReLU(), torch::nn::Linear(30,30), torch::nn::ReLU(), torch::nn::Linear(30,30), torch::nn::ReLU(), torch::nn::Linear(30,1) ) ); } torch::Tensor forward(torch::Tensor x) { return net_->forward(x); } }; int main() { torch::manual_seed(30); TT X = torch::tensor({1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0}).reshape({-1, 1}); TT Y = torch::tensor({1.0, 0.5, 1.5, 2.0, 2.5, 2.0, 2.5, 3.0, 3.1}).reshape({-1, 1}); std::shared_ptr<NN> model = std::make_shared<NN>(); torch::nn::MSELoss criterion = torch::nn::MSELoss(); torch::optim::Adam adam(model->parameters(), torch::optim::AdamOptions(0.01)); const size_t num_epochs = 1000; for (size_t epoch = 0; epoch < num_epochs; ++epoch) { TT output = model->forward(X); TT loss = criterion(output, Y); adam.zero_grad(); loss.backward(); adam.step(); if ((epoch + 1) % 100 == 0) { std::cout << "Loss: " << loss.item<float>() << std::endl; } } //model->eval(); TT test = torch::tensor({4.4, 5.5}).reshape({-1, 1}); TT predic = model->forward(test); std::cout<< "prediction is " << predic << std::endl; return 0; }单变量对多变量变种:
#include <torch/torch.h> typedef torch::Tensor TT; class NN : public torch::nn::Module { torch::nn::Sequential net_; public: NN() { net_ = register_module ( "net", torch::nn::Sequential ( torch::nn::Linear(1,20), torch::nn::ReLU(), torch::nn::Linear(20,30), torch::nn::ReLU(), torch::nn::Linear(30,30), torch::nn::ReLU(), torch::nn::Linear(30,30), torch::nn::ReLU(), torch::nn::Linear(30,2) ) ); } torch::Tensor forward(torch::Tensor x) { return net_->forward(x); } }; int main() { torch::manual_seed(30); TT X = torch::tensor({1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0}).reshape({-1, 1}); TT Y = torch::tensor({{1.0, 1.0}, {0.5, 0.5}, {1.5, 1.5}, {2.0, 2.0}, {2.5, 2.5}, {2.0, 2.0}, {2.5, 2.5}, {3.0, 3.0}, {3.1, 3.1}}).reshape({-1, 2}); std::shared_ptr<NN> model = std::make_shared<NN>(); torch::nn::MSELoss criterion = torch::nn::MSELoss(); torch::optim::Adam adam(model->parameters(), torch::optim::AdamOptions(0.01)); const size_t num_epochs = 1000; for (size_t epoch = 0; epoch < num_epochs; ++epoch) { TT output = model->forward(X); TT loss = criterion(output, Y); adam.zero_grad(); loss.backward(); adam.step(); if ((epoch + 1) % 100 == 0) { std::cout << "Loss: " << loss.item<float>() << std::endl; } } //model->eval(); TT test = torch::tensor({4.4, 5.5}).reshape({-1, 1}); TT predic = model->forward(test); std::cout<< "prediction is " << predic << std::endl; return 0; } -
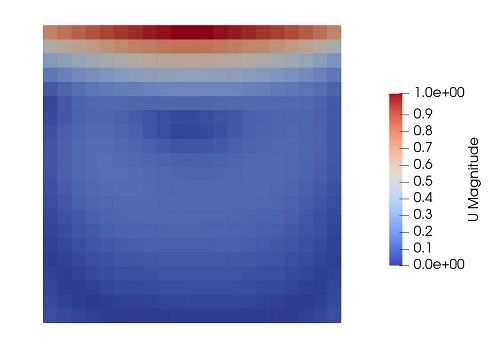
下面这个代码是个正儿八经的监督学习。下图左边是OpenFOAM算的,右边是OpenFOAM环境下libtorch训练的。

#include <torch/torch.h> #include "argList.H" #include "solver.H" #define SIZE 64 typedef torch::Tensor TT; class NN : public torch::nn::Module { torch::nn::Sequential net_; public: NN() { net_ = register_module ( "net", torch::nn::Sequential ( torch::nn::Linear(1,20), torch::nn::ReLU(), torch::nn::Linear(20,30), torch::nn::ReLU(), torch::nn::Linear(30,30), torch::nn::ReLU(), torch::nn::Linear(30,30), torch::nn::ReLU(), torch::nn::Linear(30,SIZE) ) ); } torch::Tensor forward(torch::Tensor x) { return net_->forward(x); } }; using namespace Foam; int main(int argc, char *argv[]) { #include "setRootCase.H" #include "createTime.H" #include "createMesh.H" #include "createFields.H" scalarField P0internal = P[0].primitiveField(); scalarField P1internal = P[1].primitiveField(); float* P0array = new float[SIZE]; float* P1array = new float[SIZE]; for (int i = 0; i < SIZE; i++) { P0array[i] = P0internal[i]; P1array[i] = P1internal[i]; } TT P0label = torch::from_blob(P0array, SIZE, torch::kFloat32).clone(); TT P1label = torch::from_blob(P1array, SIZE, torch::kFloat32).clone(); delete [] P0array; delete [] P1array; TT X = torch::tensor({1.0, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8}).reshape({-1, 1}); torch::Tensor Y = torch::cat ( { P0label.unsqueeze(0), P1label.unsqueeze(0) } ); //std::cout<< "Y = " << Y << std::endl; std::shared_ptr<NN> model = std::make_shared<NN>(); torch::nn::MSELoss criterion = torch::nn::MSELoss(); torch::optim::Adam adam(model->parameters(), torch::optim::AdamOptions(0.001)); for (int epoch = 0; epoch < 1500; epoch++) { //Info<< "epoch = " << epoch << nl; TT output = model->forward(X); TT loss = criterion(output, Y); adam.zero_grad(); loss.backward(); adam.step(); if ((epoch + 1) % 100 == 0) { std::cout << "Loss: " << loss.item<float>() << std::endl; } } TT test = torch::tensor({2.0}).reshape({-1, 1}); TT predic = model->forward(test); std::cout<< "prediction is " << predic.reshape({-1,1}) << std::endl; return 0; } -
-
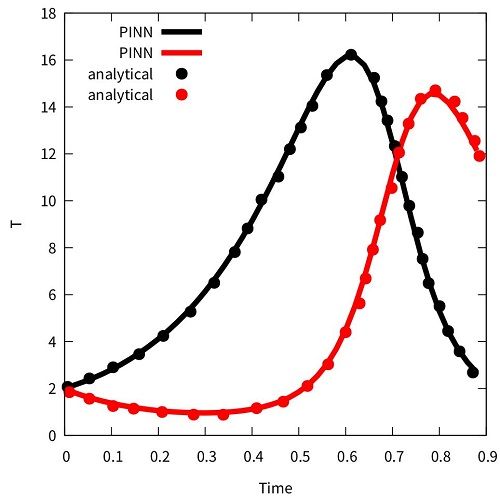
这是一个顶盖驱动流动的PINN代码。写了一天,最开始的版本植入的是守恒的形式,边界条件除了顶盖都给的零梯度,导致导数特别多。
下面这个版本我还植入的非守恒形式,然后边界条件都变成了固定值0。不过结果还是不太对。做个记录吧。整了一天这个导数

我目前怀疑边界的导数应该也是从mesh计算,而不能单独计算边界的导数。这需要大改。
#include <torch/torch.h> using namespace std; class NN : public torch::nn::Module { torch::nn::Sequential net_; public: NN() { net_ = register_module ( "net", torch::nn::Sequential ( torch::nn::Linear(2,20), torch::nn::Tanh(), torch::nn::Linear(20,20), torch::nn::Tanh(), torch::nn::Linear(20,20), torch::nn::Tanh(), torch::nn::Linear(20,20), torch::nn::Tanh(), torch::nn::Linear(20,3) ) ); } auto forward(torch::Tensor x) { return net_->forward(x); } }; int main() { torch::manual_seed(30); int iter = 1; int IterationNum = 200; auto crit = torch::nn::MSELoss(); auto model = std::make_shared<NN>(); auto adam = std::make_shared<torch::optim::Adam>(model->parameters()); // Computational domain double dx = 0.2; double dy = 0.2; auto x = torch::arange(0, 1 + dx, dx); auto y = torch::arange(10, 11 + dy, dy); auto mesh = torch::stack(torch::meshgrid({x, y})).reshape({2, -1}).transpose(0, 1); mesh.requires_grad_(true); auto leftWall = torch::stack ( torch::meshgrid({x.index({0}), y}) ).reshape({2, -1}).transpose(0, 1); auto rightWall = torch::stack ( torch::meshgrid({x.index({-1}), y}) ).reshape({2, -1}).transpose(0, 1); auto bottom = torch::stack ( torch::meshgrid({x, y.index({0})}) ).reshape({2, -1}).transpose(0, 1); bottom.requires_grad_(true); auto top = torch::stack ( torch::meshgrid({x, y.index({-1})}) ).reshape({2, -1}).transpose(0, 1); top.requires_grad_(true); auto fixedWalls = torch::cat({leftWall, rightWall, bottom}); auto u_top = torch::full({x.size(0)}, 1.0); auto v_top = torch::full({x.size(0)}, 0.0); //cout<< "mesh = \n" << mesh << endl; //cout<< "leftWall = \n" << leftWall << endl; //cout<< "rightWall = \n" << rightWall << endl; //cout<< "bottom = \n" << bottom << endl; //cout<< "top = \n" << top << endl; //cout<< "fixedWalls = \n" << fixedWalls << endl; // Iteration for (int i = 0; i < IterationNum; i++) { adam->zero_grad(); // Top boundary auto top_pred = model->forward(top); auto u_top_pred = top_pred.index({torch::indexing::Slice(), 0}); auto v_top_pred = top_pred.index({torch::indexing::Slice(), 1}); auto p_top_pred = top_pred.index({torch::indexing::Slice(), 2}); auto loss_top = crit(v_top_pred, v_top) + crit(u_top_pred, u_top); auto dpdTop = torch::autograd::grad ( {p_top_pred}, {top}, {torch::ones_like(p_top_pred)}, true, true )[0]; auto dpdyTop = dpdTop.index({torch::indexing::Slice(), 1}); loss_top += crit(dpdyTop, torch::zeros({dpdyTop.size(0)})); //cout << "loss_top\n" << loss_top << endl; // Bottom boundary auto bot_pred = model->forward(bottom); auto u_bot_pred = bot_pred.index({torch::indexing::Slice(), 0}); auto v_bot_pred = bot_pred.index({torch::indexing::Slice(), 1}); auto p_bot_pred = bot_pred.index({torch::indexing::Slice(), 2}); auto dpdBot = torch::autograd::grad ( {p_bot_pred}, {bottom}, {torch::ones_like(p_bot_pred)}, true, true )[0]; auto dpdyBot = dpdBot.index({torch::indexing::Slice(), 1}); auto loss_bot = crit(dpdyBot, torch::zeros({dpdyBot.size(0)})) + crit(u_bot_pred, torch::zeros({dpdyBot.size(0)})) + crit(v_bot_pred, torch::zeros({dpdyBot.size(0)})); // Field auto UP = model->forward(mesh); auto u_pred = UP.index({torch::indexing::Slice(), 0}); auto v_pred = UP.index({torch::indexing::Slice(), 1}); auto p_pred = UP.index({torch::indexing::Slice(), 2}); auto dpdMesh = torch::autograd::grad ( {p_pred}, {mesh}, {torch::ones_like(u_pred)}, true, true )[0]; auto dpdx = dpdMesh.index({torch::indexing::Slice(), 0}); auto dpdy = dpdMesh.index({torch::indexing::Slice(), 1}); auto dudMesh = torch::autograd::grad ( {u_pred}, {mesh}, {torch::ones_like(u_pred)}, true, true )[0]; auto dudx = dudMesh.index({torch::indexing::Slice(), 0}); auto dudy = dudMesh.index({torch::indexing::Slice(), 1}); auto dudxMesh = torch::autograd::grad ( {dudx}, {mesh}, {torch::ones_like(u_pred)}, true, true )[0]; auto dudyMesh = torch::autograd::grad ( {dudy}, {mesh}, {torch::ones_like(u_pred)}, true, true )[0]; auto dudxx = dudxMesh.index({torch::indexing::Slice(), 0}); auto dudyy = dudyMesh.index({torch::indexing::Slice(), 1}); //cout << "dudxx\n" << dudxx << endl; auto dvdMesh = torch::autograd::grad ( {v_pred}, {mesh}, {torch::ones_like(u_pred)}, true, true )[0]; auto dvdx = dvdMesh.index({torch::indexing::Slice(), 0}); auto dvdy = dvdMesh.index({torch::indexing::Slice(), 1}); auto dvdxMesh = torch::autograd::grad ( {dvdx}, {mesh}, {torch::ones_like(u_pred)}, true, true )[0]; auto dvdyMesh = torch::autograd::grad ( {dvdy}, {mesh}, {torch::ones_like(u_pred)}, true, true )[0]; auto dvdxx = dvdxMesh.index({torch::indexing::Slice(), 0}); auto dvdyy = dvdyMesh.index({torch::indexing::Slice(), 1}); auto loss_cont = crit(dudx, -dvdy); auto loss_mom1 = crit(u_pred*dudx + v_pred*dudy - 0.001*(dudxx + dudyy), -dpdx); auto loss_mom2 = crit(u_pred*dvdx + v_pred*dvdy - 0.001*(dvdxx + dvdyy), -dpdy); auto loss_pde = loss_cont + loss_mom1 + loss_mom2; //cout<< "loss_cont\n" << loss_cont << endl; //cout<< "loss_mom1\n" << loss_mom1 << endl; //cout<< "loss_mom2\n" << loss_mom2 << endl; //cout<< "loss_pde\n" << loss_pde << endl; // leftWall and rightWall auto dpdxLeft = dpdx.index({torch::indexing::Slice(0, 6)}); auto u_pred_left = u_pred.index({torch::indexing::Slice(0, 6)}); auto v_pred_left = v_pred.index({torch::indexing::Slice(0, 6)}); auto dpdxRight = dpdx.index({torch::indexing::Slice(-6, torch::indexing::None)}); auto u_pred_right = u_pred.index({torch::indexing::Slice(-6, torch::indexing::None)}); auto v_pred_right = v_pred.index({torch::indexing::Slice(-6, torch::indexing::None)}); auto loss_leftRight = crit(u_pred_left, torch::zeros({6})) + crit(v_pred_left, torch::zeros({6})) + crit(dpdxLeft, torch::zeros({6})) + crit(v_pred_right, torch::zeros({6})) + crit(u_pred_right, torch::zeros({6})) + crit(dpdxRight, torch::zeros({6})); //cout<< "loss_leftRight\n" << loss_leftRight << endl; auto loss = loss_top + loss_bot + loss_leftRight + loss_pde; //cout<< "loss\n" << loss << endl; loss.backward(); adam->step(); std::cout << iter << " " << loss.item<double>() << std::endl; iter++; } model->eval();//neglect auto results = model->forward(mesh); cout << "results\n" << results << endl; return 0; }都是在OpeNFOAM环境下,左边是我的PINN算的,下面是OpenFOAM自带的simpleFoam算的。

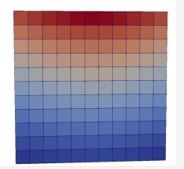
-
-
- 查看/修改OpenFOAM执行wmake时采用的Gcc版本,
OpenFOAM/wmake/rules/General/Gcc/c++CC = g++$(COMPILER_VERSION) -std=c++14 - pytorch官网下载libtorch
2.3.0版本依赖C++17
2.0.0版本依赖C++14
1.10.0版本依赖C++14 - 修改
/home/***/.bashrc,设置环境变量export LD_LIBRARY_PATH=/home/***/OpenFOAM/libtorch/lib:$LD_LIBRARY_PATH - wmake你的库(比如李老师贴的代码)PINNFoam
- 最后调用PINNFoam
- 查看/修改OpenFOAM执行wmake时采用的Gcc版本,
-
@xiezhuoyu 多谢回复,我查看了g++版本,确实是14,而且我已经成功编译了libtorch库,但是在编译一维对流方程时报错了
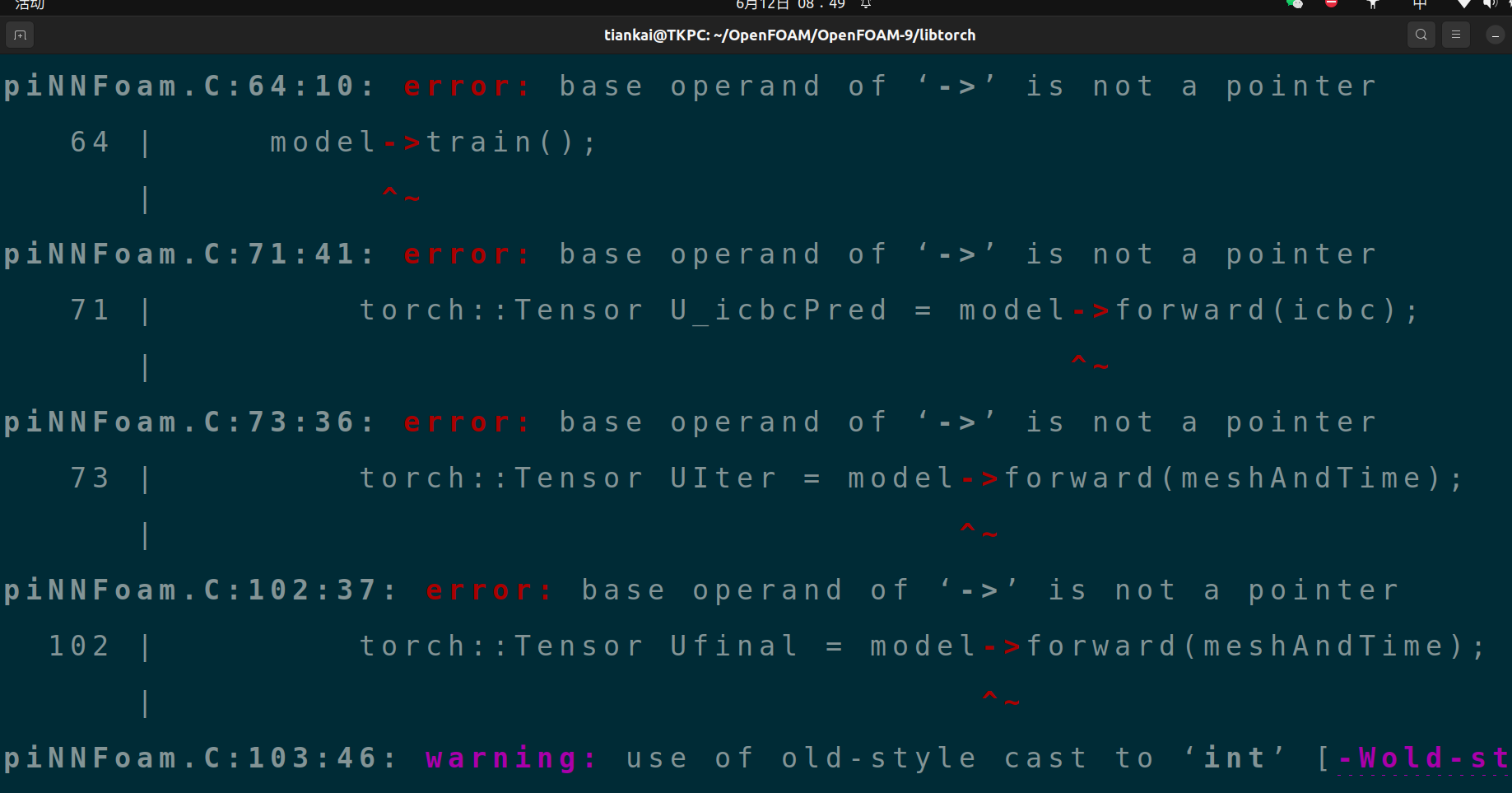
提示指针变量有错误 -
@李东岳 在 OpenFOAM外挂libtorch 中说:
我已经成功编译了libtorch库
@tiankai 我这个路子不需要编译libtorch。 你看楼上总结那个也不需要编译。我这面没有编译。就跟OpenFOAM安装一样。OpenFOAM可以直接下载装(apt install那种),也可以编译安装。你不要编译,你按照我1楼的方法用现成的,跟openfoam捆绑起来能跑起来。回头再研究编译libtorch
不好意思李老师,是我没有表述清楚,我是将libtorch解压了,用wmake了torchFoam,添加了路径。输入torchFoam,输出了上文中一样的信息,这表明libtorch库挂载成功了。
所以我想要运行PiNNFoam的代码,需要创建一个制作make文件夹,然后将PiNNFoam(一维对流方程),net.h,net.H添加到PiNNFoam的文件夹下,然后使用wmake文件夹PiNNFoam,最后调用PiNNFoam即可吧。现在使用wmake执行PiNNFoam报错了图中内容