在工作站中测试openfoam并行效率很低,大佬们帮忙看看是什么导致的呢
-
学到了,李老师,这我还是第一次知道。我一直以为单机多核的并行效率不会低于80%呢。
-
@bestucan 多谢老师,安装您说的这个软件监测了一下,用的2000万网格测得,也没看懂哪里受限了。
-
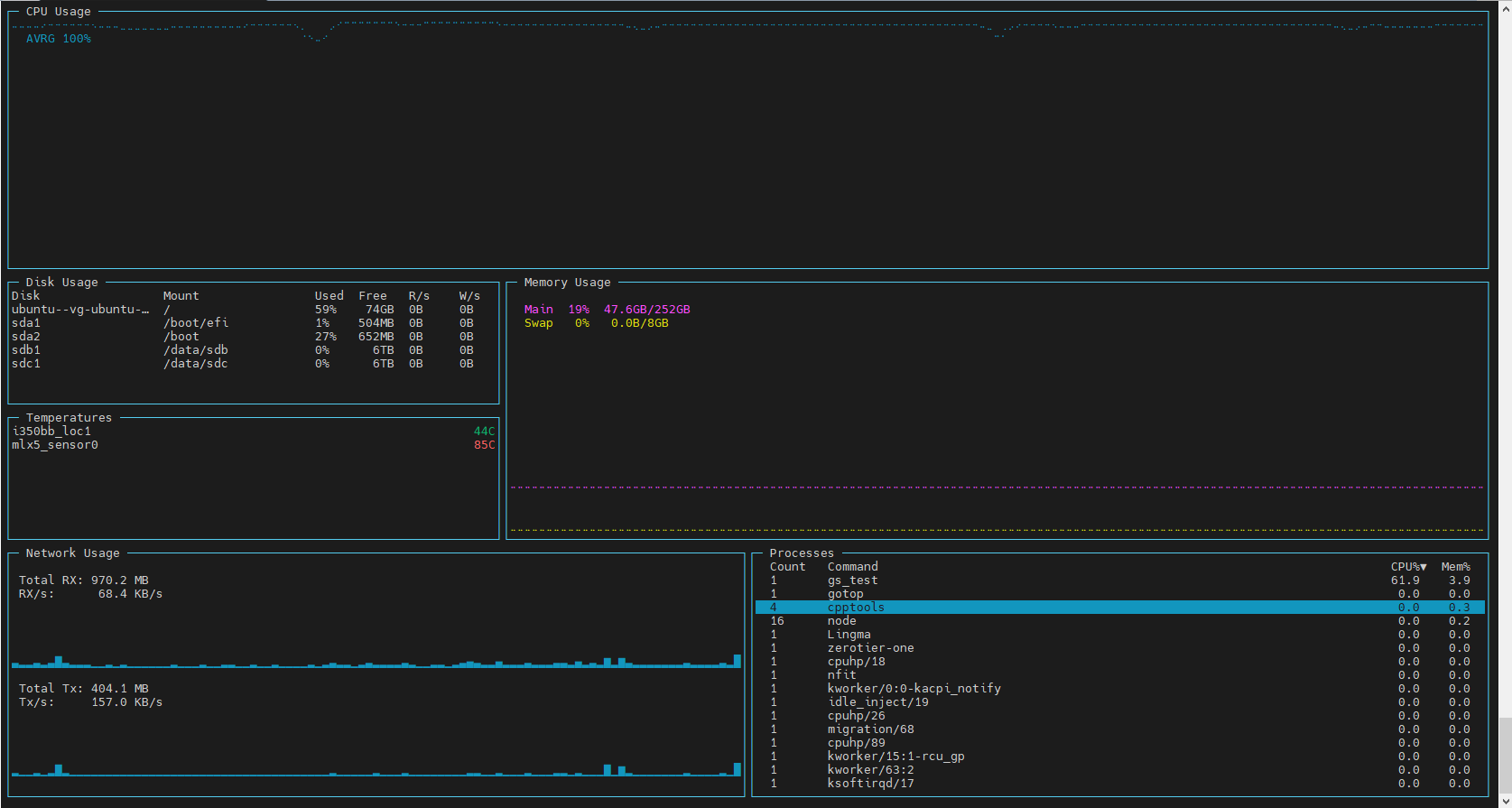
@w352405196 CPU呀,都顶到100%了。
硬盘读写都为0,说明硬盘没限制速度。
还有不小的上传下载流量。这个计算是跨节点的?
进程gs_test只占用60%左右,cpu都能顶到100%。这是还有些进程因为权限没显示出来。
可能和网络通信有关
-
@bestucan 多谢老师回复。这台工作站两个cpu,跨cpu线程计算的,不知道跟上传下载流量有关没,还是因为我这边是远程网络连接导致的。
我在指定跨cpu的线程计算时,如8和16线程,cpu很大概率上会有线程闲置或者无法满负荷运行,极少的情况下会100%运行,该情况下效率比较高;如果指定的是单cpu的线程时都是满负荷运行,但是在核数较多时效率反而较低,比如说32核。
如果是内存带宽受限的话,会体现在那个数据上呢,多谢老师解惑
-
@w352405196 两个CPU呀,那要考虑主板总线带宽的影响了。
线程开的越多,CPU交换数据越频繁。总线堵了,速度可不是上不去了。
CPU和内存交换数据也是要通过总线的。所以,程序即使往硬盘读写不频繁。但是计算一定要从内存读指令和数据的。所以,可以查查你的主板型号,看看它的总线对多CPU或者说高性能计算的支持怎么样
-
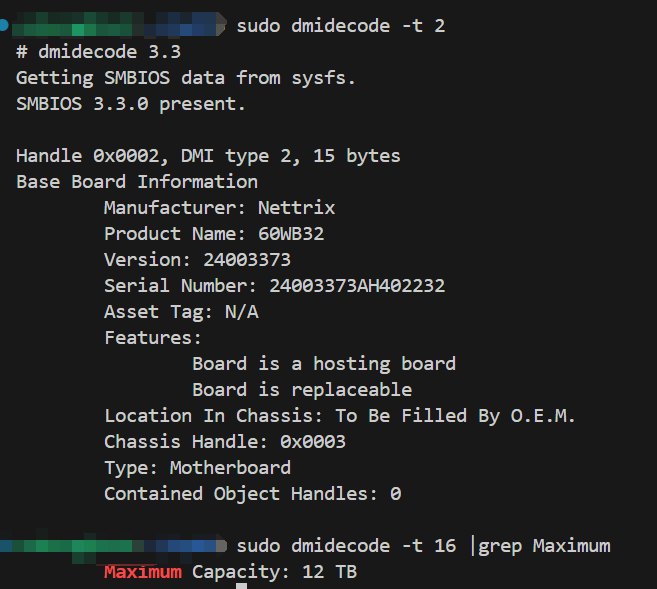
@bestucan 老师,该主板型号如下所示。我这边测试,在大网格量线程数较多时如32核跨cpu计算效率比单cpu更高,但在核数较少如8核的情况下单cpu更好。感觉跟正常理解不太一样,按理说单cpu计算性能更高才对
-
@w352405196 对于单个CPU而言,所有的核都用上,不会是最快的,但是慢多少说不清楚。
因为还要留几个核做些调度工作,(往底层说是芯片上任务分支判断、多任务切换上下文转换、堆栈策略什么的,往系统上说是系统本身有些服务进程一直在后台运行)
32核跨CPU效率高。可以解释为,对于单个CPU而言,满载32个核都用来任务,还得时不时停下任务做些任务调度工作,所以慢些。分到两个CPU。每个CPU。一半核用于调度工作,一半核用于计算任务。快些也合理。
当8核的时候。无论是单个CPU还是两个CPU运行,都会有一部分核空闲用于随时的任务调度工作。所以,分到两个CPU上反而慢一些。因为CPU间通信会耗时一些。两个CPU互相不知道对方的工作状态,不如单个CPU统一调度效率高。这个现象也可以理解。
如果把计算任务理解成打仗。不能让所有人都上战场(所有核用于计算),得留几个人搞后勤支援。否则,就得有些人一会披上铠甲打仗,一边系着围裙搞后勤。后勤保障不上,拖慢整体进度。相比于整体进度拖慢,做后勤的那个核因为做后勤而降低的打仗效率反而不重要了。
而且,核多不一定快。
核越多,核间通信的时间成本越大,核间任务调度算法越麻烦,调度效率也越低(总是难免核间互相等待对方的结果才能继续自己的)。如果横轴表示计算用的CPU核数量,纵轴表示计算用时,那应该是两头高,中间低。
影响的因素很多,得具体分析瓶颈在哪里。