decomposePar 的手动分块/手动指定计算区域分块
-
似乎之前没法出去,重新发一下
OpenFOAM 进行并行计算之前,需要讲计算区域分成若干个小块,每个小块指定一个线程进行计算。目前有的方法是simple, hierarchical, scotch 和 manual。simple 和 hierarchial 本质上是一样的,后者能选方向,scotch 尽量减少连接各个区域的面积。但是有些时候这三者都不适用的时候,就需要手动分区了。
最近做catalytic simulation,计算最繁重的地方是catalyticWall 边界, 因此想使用更多的核计算catalytic边界。理论上说最好的办法是把catalyticWall 边界平均分配到各个线程,即将catalyticWall 边界平均分成n分,由这n个subArea出发,寻找平均并且使得processor间接触面积最小的分区,但是似乎并没有找到这种方法(如果有人知道的话请不吝赐教。。),那么就出现了第二种方法,首先将计算区域划分成包含catalytic 边界的小区域A和不包含catalytic 边界的大区域B,将A继续分为n等分,分别指定给一些线程,然后B指定给另个(或多个)线程,如图所示:
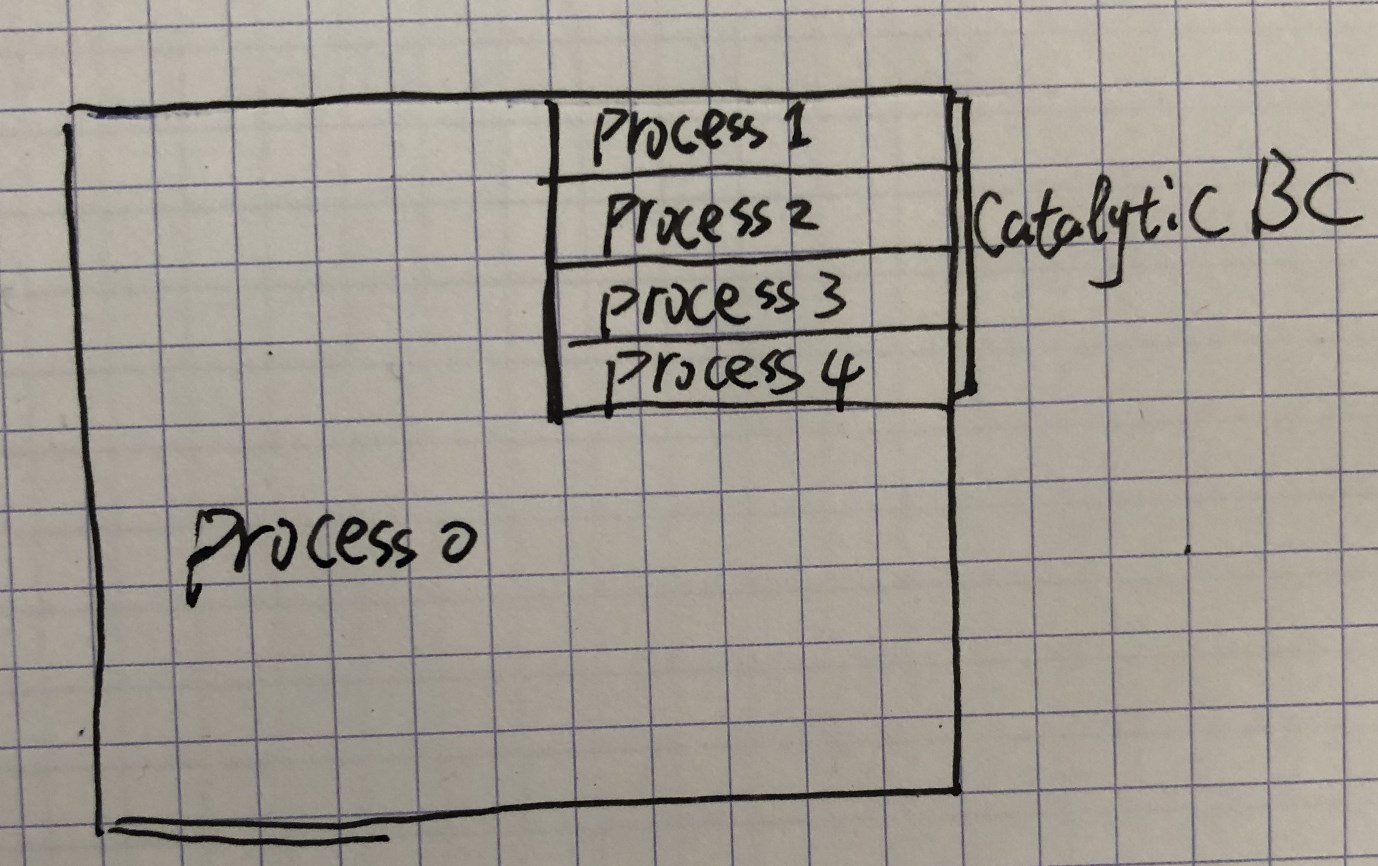
manual 方式需要一个目录文件来进行分区,但是网格数量很多的时候,手动指定并不可行,cfd-online上一篇帖子叙述了使用setFields手动分块 的一种办法,我没试过,感觉应该有更decent的办法,转过来权当抛砖引玉。步骤:
- 准备两个文件,system/setFieldsDict, /preDecomp.py ,附在本文最后,
- 使用scotch方式decomposePar,并且在0/目录下创建cellDist
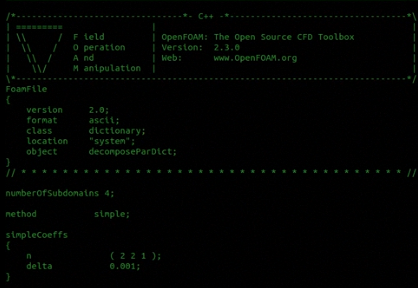
decomposePar -cellDistdesomposeParDict 内:
numberOfSubdomains 2; method scotch;- 使用setFields 创建分块(此时需要system/下有setFieldsDict),
setFields- 这一步是使用python打开"0/cellDist",修改和删除一些行,即把cellDist里面的volScalarField改为labelList,同时删除边界节点(是节点么?),如果preDecomp.py已经编辑好了,可以直接执行:
python prepDecomp.py- 最后,修改decomposeParDist, 中method 为manual, 并执行:(个人认为rm -r -processor* 是不需要的,直接decomposePar -force 就可以了,另我删除了原帖中setFields 和python prepDecomp.py)
rm -r processor* decomposePar最后附上文中setFieldsDict 和需要粘贴在prepDecomp.py中的内容,各个box可以随心
/*--------------------------------*- C++ -*----------------------------------*\ | ========= | | | \\ / F ield | OpenFOAM: The Open Source CFD Toolbox | | \\ / O peration | Version: 1.7.1 | | \\ / A nd | Web: www.OpenFOAM.com | | \\/ M anipulation | | \*---------------------------------------------------------------------------*/ FoamFile { version 2.0; format ascii; class dictionary; location "system"; object setFieldsDict; } // * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * // defaultFieldValues ( volScalarFieldValue cellDist 0 ); regions ( boxToCell { box ( 0.5 0 0 ) ( 1 0.5 1 ) ; fieldValues ( volScalarFieldValue cellDist 1); } boxToCell { box ( 0 0.5 0 ) ( 0.5 1 1 ) ; fieldValues ( volScalarFieldValue cellDist 2); } boxToCell { box ( 0.5 0.5 0 ) ( 1 1 1 ) ; fieldValues ( volScalarFieldValue cellDist 3); } ); // ************************************************************************* //# file prepDecomp.py #read file with open("0/cellDist", "r") as cdFile: lines = cdFile.readlines() #replace and delete unwanted lines lines[11] = lines[11].replace("volScalarField", "labelList") lines[12] = lines[12].replace("0", "constant") del lines[17:21] bfline = 0 for i, line in enumerate(lines): if (line.find("boundaryField") != -1): bfline = i break del lines[i:] #write file with open("constant/cellDist", "w") as cdFile: for line in lines: cdFile.write(line) -
但是我试了下,运行出了个错误,感觉搞笑得一塌糊涂,找不到constant文件??不是应该找的是constant/cellDist么?
--> FOAM FATAL IO ERROR: cannot find file file: /home/he/catalyticFOAM/case/cloneCaseStudy/constant at line 0. From function regIOobject::readStream() in file db/regIOobject/regIOobjectRead.C at line 72. FOAM exiting -
滚来滚去……~(~o ̄▽ ̄)~o 滚来滚去都不能让大家看出来我不是老师么 O_o
异步沟通方式(《posting style》from wiki)(下载后打开):
https://www.jianguoyun.com/p/Dc52X2sQsLv2BRiqnKYD
提问的智慧(github在gitee的镜像):
https://gitee.com/bestucan/How-To-Ask-Questions-The-Smart-Way -
@hurricane007 我说蜂窝只是不加其他考虑的回答你的那个问题,怎么样让接触边界小。
我觉得通信量的大小倒不是很影响并行速度,主要是区域间的互相影响。
比如如果有个长管喷嘴,照着喷嘴中心竖切分成两个区域。这样喷嘴左边和喷嘴右边都可以各自影响不是很大的一起计算。
如果是横切两个区域,一个包含喷嘴,一个不包含喷嘴。那没有喷嘴的区域在初始时间没有什么计算量。因为还没喷过来。
这是个很糙的例子,最恶劣的状况,网格分区,犬牙交错。那么计算过程更像是核之间的接力赛,你方唱罢我登台。那并行的优势是一点点都没有了。
所以要避免这样的状况,我觉得要结合边界条件对流域有个定性的预估。至于scotch的工作原理我是不懂的

滚来滚去……~(~o ̄▽ ̄)~o 滚来滚去都不能让大家看出来我不是老师么 O_o
异步沟通方式(《posting style》from wiki)(下载后打开):
https://www.jianguoyun.com/p/Dc52X2sQsLv2BRiqnKYD
提问的智慧(github在gitee的镜像):
https://gitee.com/bestucan/How-To-Ask-Questions-The-Smart-Way -
@bestucan 对的对的,我也觉得是这样,那个“很糙”的例子其实很好,当计算区域内计算负载不均衡的时候,均匀的分区其实并不能均匀分配负载在各个线程上,我想做这个手动分区其实就是想搞这个,把计算负载最大的catalytic 边界分在更多的核上算。
BTW,既然blockMeshDist里面能指定blcoks了,意味着在blockMesh里面已经是分块划分网格了,有没有一种方式直接在decomposeParDist里面指定每一个blcoks的分区方式呢? -
再update一下python的代码,不知道哪个为啥错,但是重新写了下执行对了。但是响了下应该是可以写个script执行的,如果电脑上没python。。。
#read file f1 = open("0/cellDist", "r") lines = f1.readlines() f1.close() #replace and delete unwanted lines lines[11] = lines[11].replace("volScalarField", "labelList") lines[12] = lines[12].replace("0", "constant") del lines[17:21] bfline = 0 for i, line in enumerate(lines): if (line.find("boundaryField") != -1): bfline = i break del lines[i:] #write file f2 = open("constant/cellDist", "w") for line in lines: f2.write(line) f2.close(); -
@hurricane007 比block还简单粗暴,横着分两份,竖着分两份。第三个维度没有。
滚来滚去……~(~o ̄▽ ̄)~o 滚来滚去都不能让大家看出来我不是老师么 O_o
异步沟通方式(《posting style》from wiki)(下载后打开):
https://www.jianguoyun.com/p/Dc52X2sQsLv2BRiqnKYD
提问的智慧(github在gitee的镜像):
https://gitee.com/bestucan/How-To-Ask-Questions-The-Smart-Way -
@bestucan 如果我在blockMeshDict里面定义了两个blocks,然后我想把第一个block分成两快,第二个block分成6块,有简单的实现方法么。。
-
@hurricane007 我的实际操作经验还是挺少的。没见有可以把block和分区结合一起的方法,毕竟这两个分的依据都不太一样。有个方式是manual,看起来很适合你的样子。直接指定哪个网格属于哪个分区。但没见过相关例子。



滚来滚去……~(~o ̄▽ ̄)~o 滚来滚去都不能让大家看出来我不是老师么 O_o
异步沟通方式(《posting style》from wiki)(下载后打开):
https://www.jianguoyun.com/p/Dc52X2sQsLv2BRiqnKYD
提问的智慧(github在gitee的镜像):
https://gitee.com/bestucan/How-To-Ask-Questions-The-Smart-Way -
-
@hurricane007 那这种方法挺好的

如果手动加工去关联block和分区。可以用写脚本,bash、python都行。读constant/polymesh里的数据,计算生成celllist。
这个工作量并不是很大,就是逻辑理着麻烦。
linux一切皆文本的好处,什么信息都可读,操作方法通用,容易嫁接。滚来滚去……~(~o ̄▽ ̄)~o 滚来滚去都不能让大家看出来我不是老师么 O_o
异步沟通方式(《posting style》from wiki)(下载后打开):
https://www.jianguoyun.com/p/Dc52X2sQsLv2BRiqnKYD
提问的智慧(github在gitee的镜像):
https://gitee.com/bestucan/How-To-Ask-Questions-The-Smart-Way -
@bestucan 其实这个方法是用 setFields 先赋值一个cellLabel 场,每个点的值为想分的区,再把这个场给转化成manualDist,然后再用decomposePar 根据这个manualDist 分区了。
但是我觉得可能自己分区不一定有算法分的好,那么最好就是手动分成几块,然后算法再把每块分成几小块 -
@hurricane007 这个思路挺不不错。我没见过手动分区的例子,不懂了
 加油。
加油。
 感谢诸位大神分享!
感谢诸位大神分享!