使用A100和V100GPU运行RapidCFD
-
-
@李东岳
谢谢李老师,问题已经解决了,就是这个问题。
在/etc/config/settings.sh中这个位置是可以修改一下的.export FOAM_MPI=openmpi-2.1.1 # optional configuration tweaks:之后,可以还会出现bug:
opal_shmem_base_select failed --> Returned value -1 instead of OPAL_SUCCESS按照 链接文本
修改既可.现在可以同时并行2块A100了,我在测试一下8块V100的效果.
分享一下目前的测试结果,都是LES的结果, 都是不可压缩的绕流和壁湍流问题。6000w网格的时候,一块A100都可以顶的上320个cpu进程了.
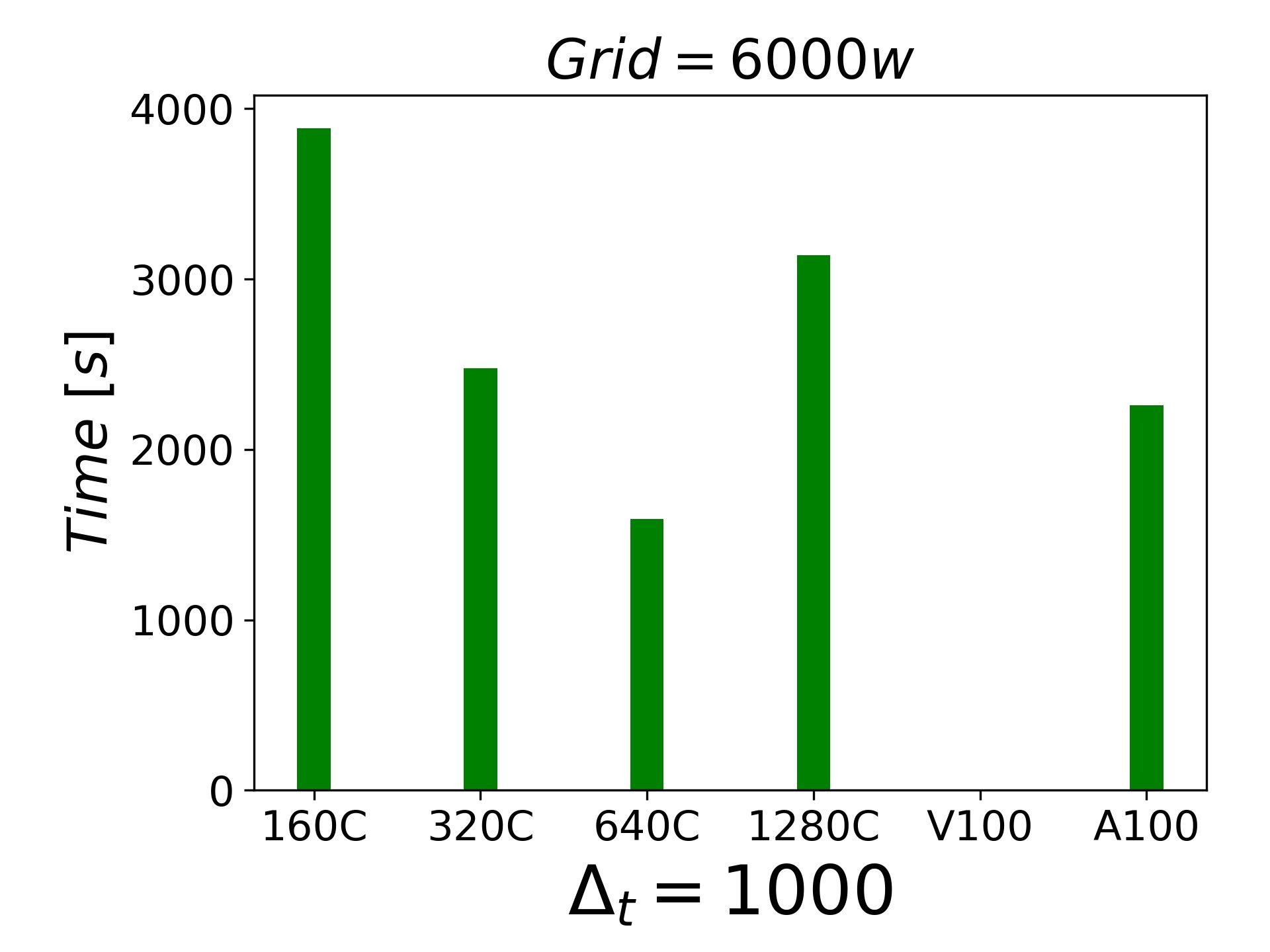
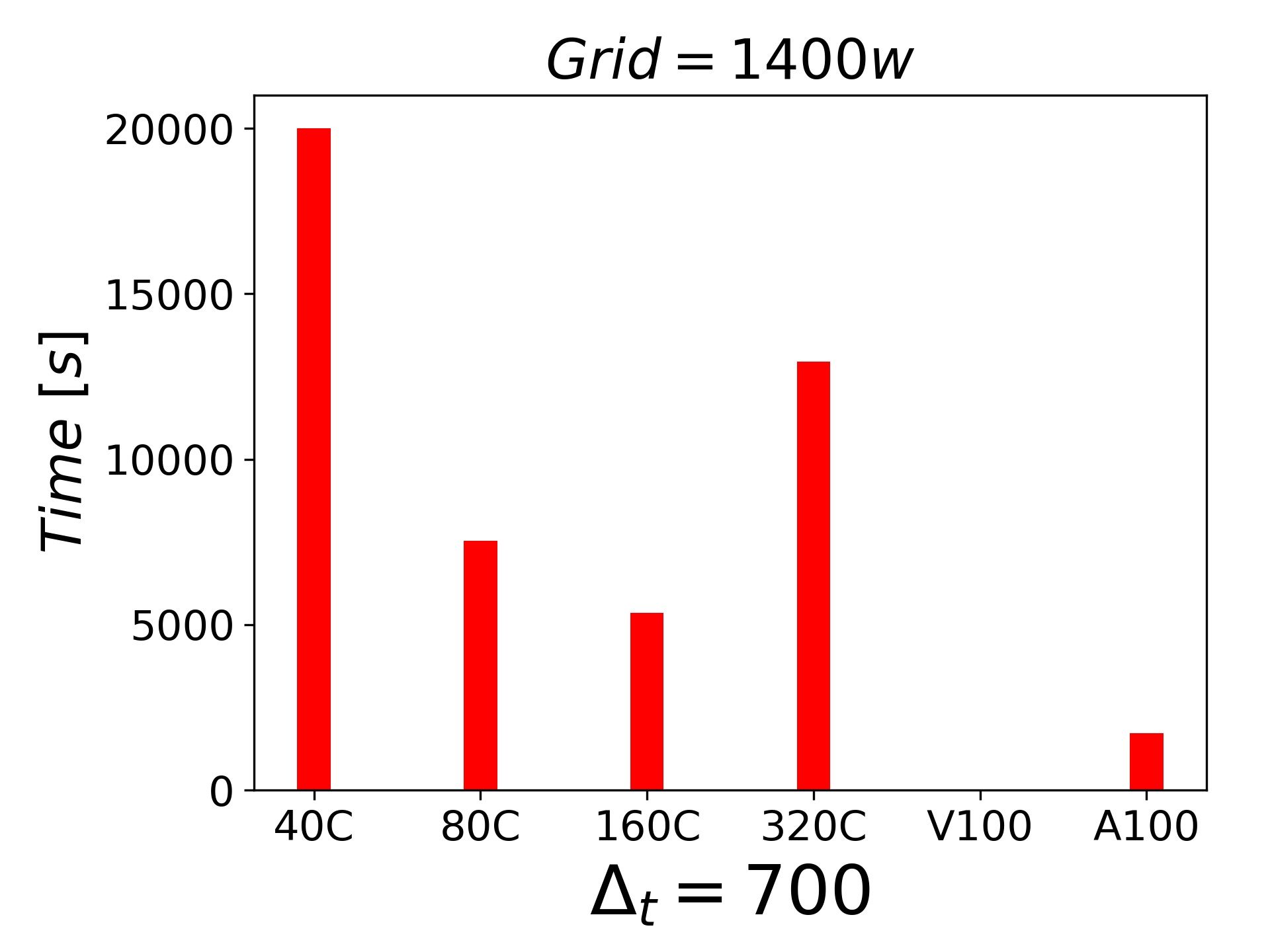
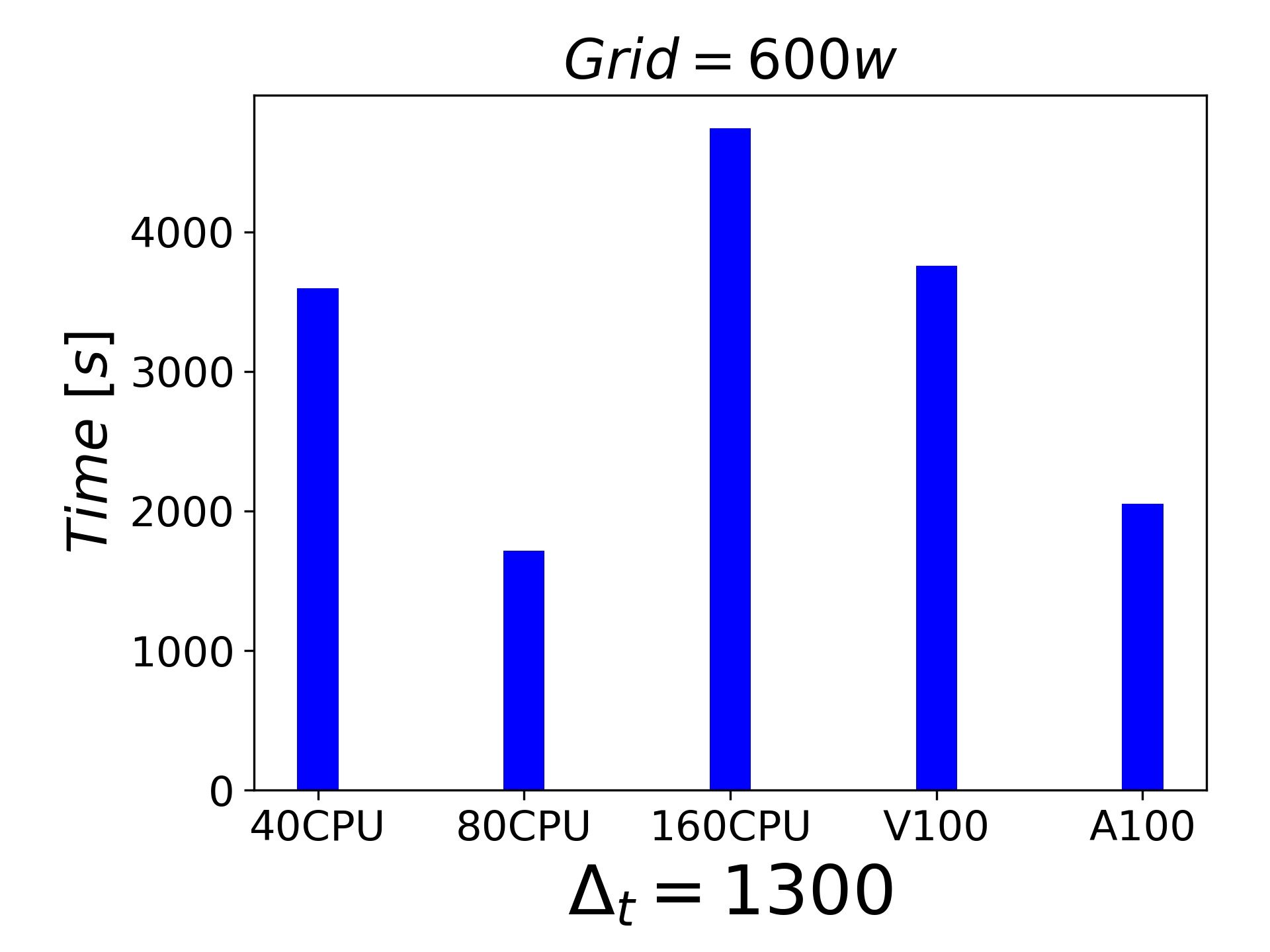
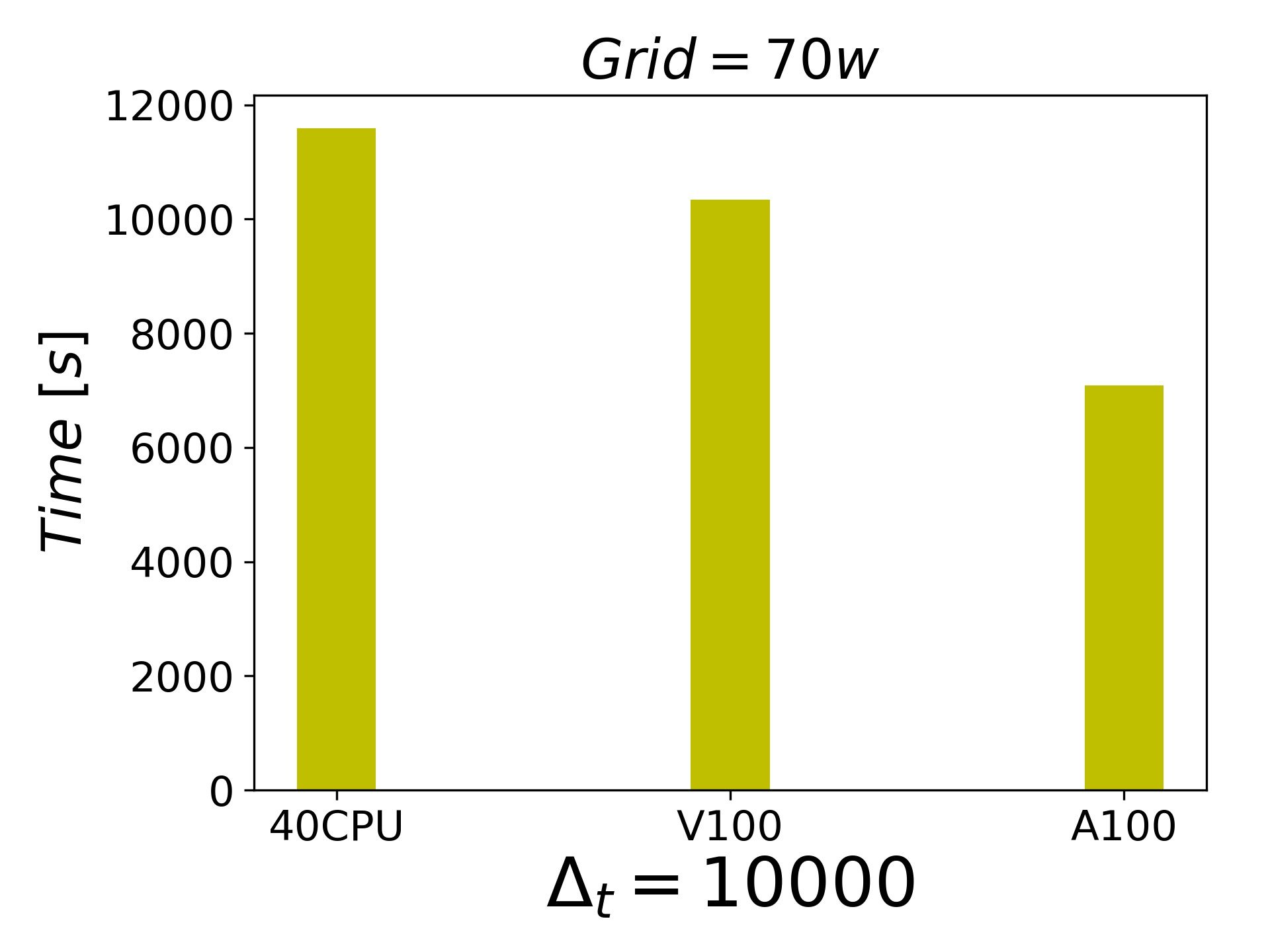
-
-
李老师,
测试结果,只能作为一个简单的参考用,而且都是针对不可压绕流的问题。加速的问题,之前论坛上就有过讨论,关于GAMG和PCG在多进程下的速度问题。我的个人观察是GAMG在OpenFoam框架下更加适合且稳定。RenumberMesh其实我了解的不多,但是个人观察发现加速程度不明显。
关于求解Ax=b的问题,那一定是有最优方法的,并且是在不断更新进步的,比如PBiCGStab 就非常快。
我个人不是做算法的,所以,只能是做一下应用。A100是组里买来给深度学习用的,我就是借着人工智能的光,测试一下。还有一个发现就是并行GPU A100 2块运算目前并没有给我带来想要的加速效果(1400W case)。短期来看,基于CPU 的集群上跑CFD 可能还是主流。但是,价格决定市场,如果GPU价格能够降到可以接受的程度,就不一定了。
以上都是自己跑着试试看的,仅供参考. -
 李 李东岳 被引用 于这个主题
李 李东岳 被引用 于这个主题
