哈哈哈,没事,谢谢东岳老师!
悬
悬铃神木
@悬铃神木
帖子
-
如何把volScalarField中的数据转化为double数组? -
如何把volScalarField中的数据转化为double数组?差不多,
U[cellID].x(), U[cellID].y(),之类 -
如何把volScalarField中的数据转化为double数组?是这样的,我想在求解过程中使用python做一些处理,要把流场数据传到python,处理后在传回,关于在of求解过程中调用python,我找到了一篇帖子:OpenFOAM 与 python 代码之间的通信
但是volScalarField这样一个类,python肯定不能识别,请问我如何能单独把流场的值作为double数组提取出来?
如果不能把整个流场值变成一个double数组,能每个cell挨个提取出来也是极好的。
我尝试去代码里找volScalarField的结构,但模板套模板实在没读明白,希望各位老师大牛们能不吝赐教。
-
S-A模型是如何处理湍动能k的?@wwzhao 嗯嗯,明白了,非常感谢您的解答!
-
S-A模型是如何处理湍动能k的?哦哦,感谢
如果是吸收到压力梯度项里去了,那需要对压力梯度项或压力方程做修正吗? -
S-A模型是如何处理湍动能k的?在构建湍流模型时,雷诺应力根据Boussinesq假设可写为
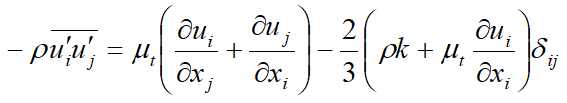
S-A模型中,建立了涡粘系数nut的输运方程,可由此得到nut,那么上式中的k是怎么处理的?
看的几个资料中都没有提及这个部分,请各位老师解个惑
-
可以讨论一个编程问题吗?这样写C++代码效率为何这么低?是我应该感谢cfd中文网的各位老师,对我的帮助很大.
另外,我测试的这个构造函数和析构函数只承担了new和delete一个double[]的任务,如果是功能更复杂的构造函数,就不好说了。 -
可以讨论一个编程问题吗?这样写C++代码效率为何这么低?是的,调用1000000次构造函数和1次,带来的差别不大
-
可以讨论一个编程问题吗?这样写C++代码效率为何这么低?@Zephyr 嗯嗯,感谢,我去尝试一些库
-
可以讨论一个编程问题吗?这样写C++代码效率为何这么低?谢谢您的回答!我试了下不使用动态分配而用固定大小的数组p[10000]来代替,确实提高了一些效率,从10S+变成了7S+。
但我这里确实需要动态分配,因为我希望做成一个有一定通用性的矩阵类来储存各种流场信息,我无法在编程时就知道需要多大内存,也许这次计算只要几千网格,也许下次就需要几千万网格。 -
可以讨论一个编程问题吗?这样写C++代码效率为何这么低?谢谢您的回答!试了一下确实是编译器优化带来的问题,我在linux系统下使用g++编译这串代码,以下分别是优化等级-O0(无优化)、-O1、-O2、-O3时得到的运行速度:
-O0 Time1 = 47.759S Time2 = 29.2934S -O1 Time1 = 16.7366S Time2 = 4.35349S -O2 Time1 = 11.9593S Time2 = 1e-06S -O3: Time1 = 12.2002S Time2 = 0S可见无优化时虽然我这种使用类的写法也要慢一些,但两者在一个数量级上,优化等级越高,直接使用数组的方法优势就越大了……
编译器的优化好神奇哦!
看来以后还是尽量去用别人写的成熟的函数库吧……
-
可以讨论一个编程问题吗?这样写C++代码效率为何这么低?7.415S,确实快了一些。但是这样写相当于改变了两个被乘数组之一,这样限制了它的使用方式,像C=A+A*B这样的或者更复杂的表达式就很难写了。我试了一下,确实如楼下所言是优化的问题,零优化情况下就和直接用数组的方式没有这么大的差距。
-
可以讨论一个编程问题吗?这样写C++代码效率为何这么低?希望像matlab那样可以直接在矩阵层面操作,这样写出程序来简洁一些,我不知道有哪种自带的类可以满足,我只试过vector,但是并不比我自己写的类快。
-
可以讨论一个编程问题吗?这样写C++代码效率为何这么低?谢谢东岳老师,测试了一下确实是这样,构造和return这个类耗费时间很多……
但是没想到好方法……要实现相关功能+-*/必须返回一个相同的类……
不知道成熟的代码是怎么解决这个问题的
-
可以讨论一个编程问题吗?这样写C++代码效率为何这么低?这个循环嵌套直接用double数组速度很快啊,用了0.492S
上面那个用了我写的类的地方:for (int t = 0; t < 1000000; t++)C = A * B;这个地方很慢,做相同的事情用了 10.4S
-
可以讨论一个编程问题吗?这样写C++代码效率为何这么低?我在写一个CFD程序的时候碰到的问题,我想使用c++的特性把double数组封装成一个新的类,这样就可以重载运算符,像使用matlab那样直接进行矩阵层次的操作。
比如,在c++里要分别对元素操作:for(int i=0;i<10000;i++)C[i]=A[i]+B[i]用matlab就可以直接写:
C=A+B;但我写成一个类后,运算效率却比直接这样运行慢太多,甚至比matlab慢很多(C++应该比matlab快才对吧?)
比如如下代码:#include "pch.h" #include <iostream> #include <time.h> class Array { public: Array(int S):Size(S) //构造函数 { p = new double[Size]; } Array(int S, double n):Size(S) //构造函数 { p = new double[Size]; for (int i = 0; i < Size; i++)p[i] = n; } ~Array() //析构函数 { delete[] p; } Array & operator=(const Array & A) //重载= { if (this == &A) return *this; delete[] p; Size = A.Size; p = new double[Size]; memcpy(p, A.p, Size * sizeof(double)); return *this; } Array operator*(const Array & A) //对应元素* { Array result(Size); for (int i = 0; i < Size; i++)result.p[i] = p[i] * A.p[i]; return result; } private: int Size; double *p; }; int main() { clock_t time1, time2; Array A(10000, 1.0); Array B(10000, 1.0); Array C(10000, 1.0); time1 = clock(); for (int t = 0; t < 1000000; t++)C = A * B; time2 = clock(); std::cout<< "Time1 = " << (double)(time2 - time1) / CLOCKS_PER_SEC << "S" << std::endl; //测试直接使用double数组的速度 double a[10000]; double b[10000]; double c[10000]; for (int i = 0; i < 10000; i++)a[i] = 1, b[i] = 1; time1 = clock(); for (int t = 0; t < 1000000; t++) for (int i = 0; i < 10000; i++)c[i]=a[i] * b[i]; time2 = clock(); std::cout << "Time2 = " << (double)(time2 - time1) / CLOCKS_PER_SEC << "S" << std::endl; system("pause"); return 0; }输出:
Time1 = 10.4S
Time2 = 0.492S
使用对象的时候慢了20多倍用matlab做相同工作的时候:
A=ones(10000,1); B=zeros(10000,1); t1=clock; for i=1:1000000 C=A.*B; end t2=clock; T=etime(t2,t1)输出:
T =4.8610
我这样写是否犯了什么错误? 这种情况下应该如何提升c++的效率呢?
这种情况下应该如何提升c++的效率呢? -
一个奇怪的问题,OpenFOAM在断网的时候终止计算@我是河滩 MPI是OpenFoam官方使用的并行方法,现在来看应该是只能用这个。我没有研究过并行的代码,复不复杂应该取决于你对openFoam求解器改动程度的大小,小改动一般不用重写并行的代码。
-
求关于LBM方法的算例或者教程@FluidGao 嗯嗯,感谢。
-
求关于LBM方法的算例或者教程@FluidGao 谢谢您的解答,dugks和LBM都基于BGK对玻尔兹曼方程进行离散,但是数值方法上是不是有很大差别?因为我最近试用了dugksFoam这个求解器
:dugksfoam-求解离散速度boltzmann模型方程的求解器
里面有个简单的cavity算例,但是感觉计算速度较慢,无法与LBM的计算效率相比。 -
求关于LBM方法的算例或者教程@东岳 嗯嗯,十分感谢,我再去多读点文章,兴许就懂了