并行效率疑问
-
你是在哪个超算中心跑的算例?用的是什么规格的机器
-
我是在 Université de Sherbrooke 的长毛象2号超算上算的。这篇帖子的一楼最后我详细描述了硬件。
我没有在专门搞CFD的组里搞CFD,机时的分配只有100-CPU年。
-
@random_ran 在超算上安装哪个版本的openfoam?是自己安装的么?我现在跑算例要在超算上计算,现在还处在调研阶段,对超算的情况不是很了解。希望你能多给我一些建议
-
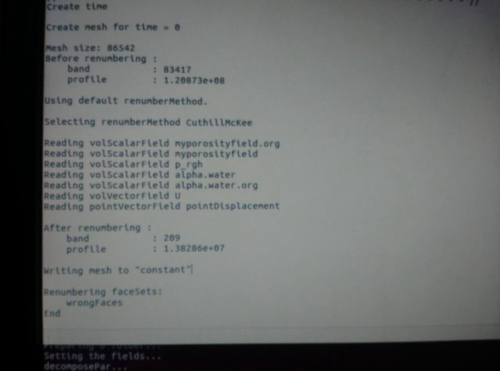
@random_ran renumberMesh这个命令你用过么?(我看贴上有人用过)用过的话你跑的是什么算例模型,计算效率提高了多少,计算结果准确么?我的算例也是圆柱绕流湍流模型验证 是否可用这个命令?
-
@random_ran
顶长毛象

@bingningmeng45
renumberMesh看你需求吧,锦上添花的东西,不用也可以,用了更好,莫非你并行遇到了瓶颈。 -
@random_ran renumberMesh 这个如何操作运行?直接在终端输入吗
-
建议你这样做:
cd $FOAM_TUTORIALS grep -rnw './' -e "renumberMesh"然后
emacs ./incompressible/pisoFoam/les/motorBike/motorBike/Allrun就会发现你想要的东西了。
我的OpenFOAM版本是v4.1。
操作系统是CentOS Linux release 7.3.1611 (Core)。祝好。
-
最近看了看这个
renumberMesh,觉得可能有一些更深入的算法在里面,看完之后,个人觉得不必深究了,就类似OpenFOAM中的mpi库一样,除非你专门做mpi的。大体思路就是楼上们说的减少带宽。比如在求解100阶矩阵的时候,现存带宽可能为30,在进行迭代预处理的时候,可能会产生填入操作,但是依然位于带宽之内。renumberMesh或者在计算图形学中的reordering可以通过将矩阵和Adjacency matrix(不知道中文是什么)联系起来,重新排序,减少带宽,降低存储。在大型计算中,可以降低内存存储,大体就是这个意思。renumberMesh中植入的是Cuthill–McKee algorithm,详细了解可google。个人觉得有点偏离CFD,了解了解就好。 -
- ilu0没有填入,of玩的ldu全是用的不填入的算法,不然ldu数据结构包不住,得像aeroFoam那样玩更高级的数据结构,
- ldu矩阵renumber不降低单次迭代的flops数量!那么省出来的时间必须有个说法,要么谱半径更小,收敛所需迭代数减少,要么平均每个flops用时减少(cache命中率提高)。总时间=迭代数每次迭代的flops数每个flops平均用时,对吧。
- renumber有效性说明现代cfd程序更多地受限于储存速度,cache命中率啥的,这个东西是有瓶颈的,未来cfd程序的套路可能就得变了。
- 你说的半带宽那套是针对banded structure的老的数据结构了,算法和数据结构是配套的,单看算法不看数据结构没有任何意义。
-
ilu0没有填入,of玩的ldu全是用的不填入的算法
你说的半带宽那套是针对banded structure的老的数据结构了在另一个帖子我也看到你说的LDU,这只是OpenFOAM存储矩阵的方式,没有任何算法的存在意义,OpenFOAM编程可以酸则LDU,也可以选择Coordinate list (COO),也可以选择List of lists (LIL)。ILU0是ILU0算法,LDU是OpenFOAM的存储矩阵的方式。我觉得你弄混了。
另外,矩阵存在带宽是客观存在的,不管你怎么存储。是LDU还是LIL。
矩阵存储和带宽是两个概念:https://en.wikipedia.org/wiki/Sparse_matrix#Compressed_sparse_row_.28CSR.2C_CRS_or_Yale_format.29
对ILU矩阵进行reordering是另一个概念:
Saad, Yousef. Iterative methods for sparse linear systems. Society for Industrial and Applied Mathematics, 2003. -
对ILU矩阵进行reordering是另一个概念:
你弄混了,从来没有ILU矩阵,是ldu矩阵吧。
COO/LIL都是sparse matrix的储存格式之一,但是不同储存格式做matrix product或者其他矩阵操作时效率是不一样的,比如CSR和CSC一个做M*x效率高,另一个做transpose(M)*x效率更高。这就是我说的具体数据结构和算法是相关的,一个操作在COO和LDU上的时间复杂度是不一样的。但是很容看出来,ldu矩阵下,很多操作的浮点操作数flops(差不多就是时间复杂度)不随reordering变化。
同时OF默认实现的只有LDU矩阵,没有coo/lil格式的,除了一些GPU扩展。所以OF没法直接调用petsc,也没有依赖别的线性代数软件包,blas,lapack之类的一个没用上,代码也很臃肿。
ILU0是fill in=0的ILU算法,可以基于任何矩阵实现,但是对于sparse matrix来说,fill in为0意味着前后indexing的部分可以不用动,只要把data部分改了就行,甚至指向另一个data_ilu就可以了。OF LDU matrix相当于所有OF里的矩阵的indexing部分都是一样,你能改变的只有data_ptr,所以OF只能玩ilu0,玩ilu1都不行。虽然OF的ldu是很紧凑高效的矩阵内存结构,但是还是有局限性的。
我关注的问题是为什么矩阵减小带宽会带来加速?用半带宽解释我觉得潜在假设就是:同样的矩阵内容,半带宽小==矩阵操作快。但是操作数不变的情况下操作加快了,就是cache的问题了。
-
我关注的问题是为什么矩阵减小带宽会带来加速?
如果去看
renumberMesh或者ANSYS关于reorder的描述,并没有说加快计算,只是说减少带宽和提高内存使用率。Renumbers the cell list in order to reduce the bandwidth, reading and renumbering all fields from all the time directories.Reordering the domain can improve the computational performance of the solver by rearranging the nodes, faces, and cells in memory. The Mesh/Reorder submenu contains commands for reordering the domain and zones, and also for printing the bandwidth of the present mesh partitions. The domain can be reordered to increase memory access efficiency, and the zones can be reordered for user-interface convenience. The bandwidth provides insight into the distribution of the cells in the zones and in memory. -
这个说得比较清楚。内存效率提升,但是也没说计算浮点操作数减少。
%pylabUsing matplotlib backend: Qt5Agg Populating the interactive namespace from numpy and matplotlibA矩阵是对角占优的矩阵
A=array([5 ,-2 ,0 ,0 ,0, -2 ,5,-2,0,0, 0 , -2, 5,-2,0, 0,0,-2,5,-2, 0,0,0,-2,5]) A = A.reshape([5,5]) Aarray([[ 5, -2, 0, 0, 0], [-2, 5, -2, 0, 0], [ 0, -2, 5, -2, 0], [ 0, 0, -2, 5, -2], [ 0, 0, 0, -2, 5]])P矩阵是排列矩阵,交换第一个元素和第5个元素
P=array([0 ,0 ,0 ,0 ,1, 0,1,0,0,0, 0 , 0, 1,0,0, 0,0,0,1,0, 1,0,0,0,0]) P = P.reshape([5,5]) Parray([[0, 0, 0, 0, 1], [0, 1, 0, 0, 0], [0, 0, 1, 0, 0], [0, 0, 0, 1, 0], [1, 0, 0, 0, 0]])排列矩阵的转置是自身的逆
P.T.dot(P)array([[1, 0, 0, 0, 0], [0, 1, 0, 0, 0], [0, 0, 1, 0, 0], [0, 0, 0, 1, 0], [0, 0, 0, 0, 1]])作用到矩阵A上,生成矩阵B
B=P.T.dot(A).dot(P) Barray([[ 5, 0, 0, -2, 0], [ 0, 5, -2, 0, -2], [ 0, -2, 5, -2, 0], [-2, 0, -2, 5, 0], [ 0, -2, 0, 0, 5]])上下三角矩阵和对角矩阵
#GS iteration L=tril(B,-1) Larray([[ 0, 0, 0, 0, 0], [ 0, 0, 0, 0, 0], [ 0, -2, 0, 0, 0], [-2, 0, -2, 0, 0], [ 0, -2, 0, 0, 0]])D=diag(diag(B)) Darray([[5, 0, 0, 0, 0], [0, 5, 0, 0, 0], [0, 0, 5, 0, 0], [0, 0, 0, 5, 0], [0, 0, 0, 0, 5]])U=triu(B,1) Uarray([[ 0, 0, 0, -2, 0], [ 0, 0, -2, 0, -2], [ 0, 0, 0, -2, 0], [ 0, 0, 0, 0, 0], [ 0, 0, 0, 0, 0]])M_GS is Gauss-Seidel iter. matrix
M_GS=inv(L+D).dot(U) M_GSarray([[ 0. , 0. , 0. , -0.4 , 0. ], [ 0. , 0. , -0.4 , 0. , -0.4 ], [ 0. , 0. , -0.16 , -0.4 , -0.16 ], [ 0. , 0. , -0.064, -0.32 , -0.064], [ 0. , 0. , -0.16 , 0. , -0.16 ]])spectral radius of GS iter.
spectral_radius_GS=max(abs(linalg.eig(M_GS)[0])) spectral_radius_GS0.48000000000000026M_J is Jacobi iter. matrix
M_J=inv(D).dot(U+L) M_Jarray([[ 0. , 0. , 0. , -0.4, 0. ], [ 0. , 0. , -0.4, 0. , -0.4], [ 0. , -0.4, 0. , -0.4, 0. ], [-0.4, 0. , -0.4, 0. , 0. ], [ 0. , -0.4, 0. , 0. , 0. ]])spectral radius of iter. matrix
spectral_radius_J=max(abs(linalg.eig(M_J)[0])) spectral_radius_J0.69282032302755092Compare A with B
L,D,U=tril(A,-1),diag(diag(A)),triu(A,1) M_GS=inv(L+D).dot(U) spectral_radius_GS=max(abs(linalg.eig(M_GS)[0])) spectral_radius_GS0.47999999999999987对比可以看出来,reorder之后迭代矩阵谱半径几乎没变化。说明加速主要来源于内存访问效率的提高。
某种意义上来说,说明CPU没吃饱,上菜速度太慢了。以后pde模拟程序的优化方向大概应该是加快上菜速度。。。