集群上并行测试OpenFOAM,并行效率并没有比单节点提升
-
一个节点64核心:平均单步19.18s
五个节点320核心:平均单步7.1s
所以你期望的是有5倍的scale吧?5节点达到4s左右。
我在超算平台上测试过128核心,采用完全相同的计算设置,平均单步6.65s
这个比不了。硬件不一样。我们这样同样64核的计算速度都不一样。可能他们的CPU更暴力。不能这么比。你只能看你们自己这个机架式,能否达到你的scale预期。
我建议你这么跑,对比总时间,而不是平均每步的时间,比如你把这个表格填一下:
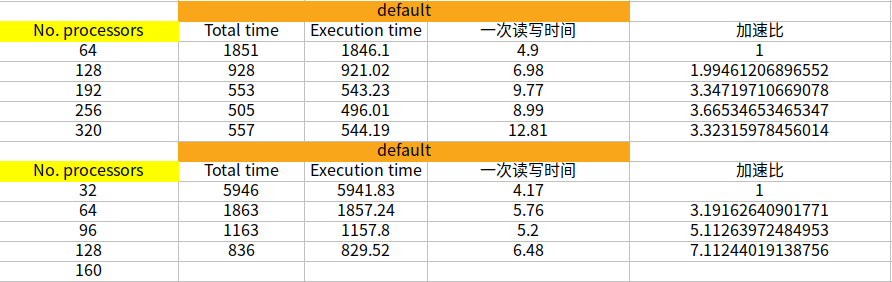
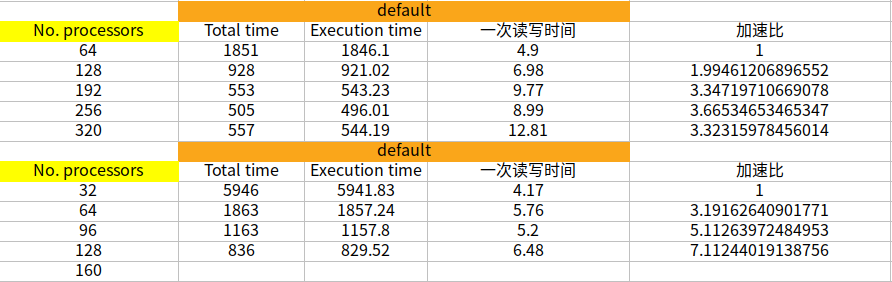
1500万,icoFoam 1节点64核100步,总共 ___ 秒 2节点128核100步,总共 ___ 秒 3节点192核100步,总共 ___ 秒 4节点256核100步,总共 ___ 秒 5节点320核100步,总共 ___ 秒然后你看一下能否做到scale的线性。同样你还可以测试下:
1500万,icoFoam 1节点32核100步,总共 ___ 秒 2节点64核100步,总共 ___ 秒 3节点96核100步,总共 ___ 秒 4节点128核100步,总共 ___ 秒 5节点160核100步,总共 ___ 秒看一下能否做到scale的线性。
另外你说的Fluent没问题。是什么没问题,能达到线性的scale,还事什么
-
-genv FI_PROVIDER tcp
这一条表示你指定使用 tcp 网络通信,所以很可能你的节点间通信就没用到 infiniband。
建议先去掉 -genv FI_PROVIDER tcp ,这样mpi应该会默认选择一个可用且最快的选项。如果不行,那么参考
https://www.intel.com/content/www/us/en/develop/documentation/mpi-developer-guide-linux/top/running-applications/fabrics-control/ofi-providers-support.html
这里的说明选择一个跟你硬件匹配的 FI_PROVIDER。 -
@sjlouie91 在 集群上并行测试OpenFOAM,并行效率并没有比单节点提升 中说:
-genv FI_PROVIDER mlx
这个参数我没用过。像 @lzf 说的,你可以试下
dapl,像 @xpqiu 说的,你可以试下把-genv FI_PROVIDER tcp去掉。但是有的 mpi 它的 FI_PROVIDER 的默认值是 PSM2,这样的话如果不加参数,单节点并行也无法跑,加上 -genv FI_PROVIDER tcp 或者 -genv FI_PROVIDER shm 就可以正常跑了
还有这样的mpi
-
@李东岳 在 集群上并行测试OpenFOAM,并行效率并没有比单节点提升 中说:
估计他就是双倍来了
那就是相对速度了,自己跟自己比

@sjlouie91 这个:https://www.top500.org/project/linpack/ 专门测超算性能的。但是流体计算的效率,影响因素太多。用李老师网站上大家都用的算例比对更容易找着对比点。
还有一个方法,开始计算后观察系统各项指标,看看哪个满负荷,哪个就是瓶颈。https://github.com/cjbassi/gotop 这个是终端界面的系统监视器。看看运行算例的时候是 CPU ,还是硬盘读写,还是网络通信,还是内存是爆满的。可以对比 fluent 运行的时候的不同。找到瓶颈后再排查比较有目标。
-
@李东岳
应该走的是infiniband,我还试过更改-genv I_MPI_FABRICS shm:ofi为shm:dapl,但是提示只有shm:ofi和ofi两种。
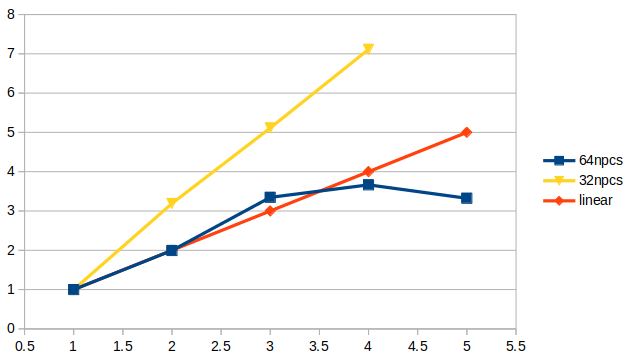
此外,除了一个节点使用32核心,我还测试过1个节点使用48和56核心,我发现不知道有没有可能是计算瓶颈的问题,我只要是用到240核上,每步计算的时长就没法再减小了。1节点64核100步,总共1851s 2节点128核100步,总共928s 3节点196核100步,总共553s 4节点256核100步,总共505s 5节点320核100步,总共557s 1节点32核100步,总共5946s 2节点64核100步,总共1863s 3节点96核100步,总共1163s 4节点128核100步,总共836s 5节点160核100步,总共616s 5节点240核100步,总共526s 5节点280核100步,总共567s请问李老师你们测试采用的算例是什么?